3rd Place at FGVC
I got third place in a competition at an academic conference on computer vision.
Academic Conferences and Computer Science
Computer Science is a field that moves at a blazing pace. Because journals take a long time to review and publish, much of the new work is premiered as a paper at an academic confernece. These conferences are hubs of new discovery, and having good publications at top conferences is one of the hallmarks of a successful computer scientist. Many of these conferences have smaller workshops where they discuss a subdiscipline of the field.
CVPR and FGVC
One of the premier conferences in computer vision is CVPR (Computer Vision and Pattern Recognition). This year, I participated in a competition as part of the FGVC (Fine Grained Vision in Computing) workshop at CVPR. Fine-Grained computer vision deals with more nuanced tasks. For example, whereas determining whether an image is of a mushroom is fairly simple, determining the species of mushroom is much more difficult, often relying on fine details.
News Unmasked Competition
Each year, there are several competitions at FGVC. One of them is mushroom identification (example from earlier), another has to do with classifying breeds of snakes. This year they added a new competition, News Unmasked. Here's the information: (copied from their website)
Overview
Motivation:
The News Unmasked competition aims to explore the limitations of large image-language models in understanding the relationship of an image with a headline. Large language model(LLMs) have been successfully used in natural language processing tasks, such as text classification and language generation and are increasingly being used in real world applications. One such field is journalism where these models can potentially be used for headline generation. LLM based models for text generation can be used to generate headline, which - though factually correct - might not be best suited for the chosen image in a publication.
Since headlines and images often work together to communicate an emotion to a reader, the competition aims to understand how the images are related with the semantic characteristics of the text (headline)
Data and Task collection:
In this competition, participants are expected to predict masked words in headlines associated with a given image, considering the subject, image context, the emotional impact of the image, etc. The challenge explores the effectiveness of large models in generating headlines, with the aim of improving our understanding of the impact of image choice on headline perception and vice versa. Such an understanding of relationships between language and images are important for the application of large models.
The dataset consists of images and their associated news section, paired with headlines that have a few words masked. The goal is to predict the missing words in the headlines.
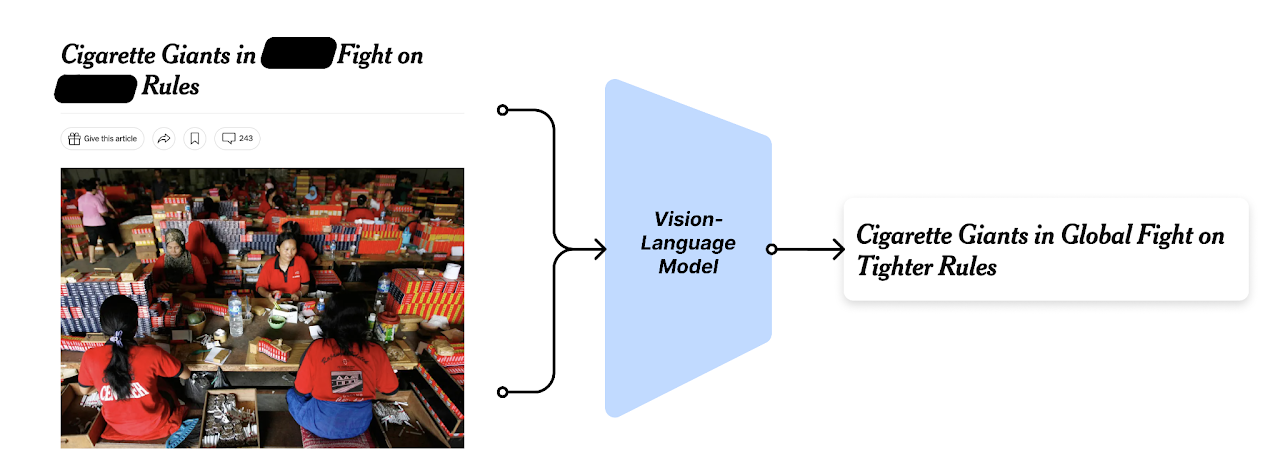
The above illustration shows an example of a headline-image pair as seen in the New York Times publication. The image above shows “many people” (objects) of a certain ethnicity, “working” (activity) with a certain kind of “facial expression.” “Cigarette,” though not clearly visible in the image, is explicit in the headline. The keywords convey a certain emotion that can affect the choice of predicted masked words in the sentence “Cigarette Giants in [MASK] Fight on [MASK] Rules.” For example, “local” fight and “lighter” rules doesnt fit with the narrative of “international news about many people of a certain ethnicity working with cigarettes.”
What I Did
If you've been reading this blog for a while, you've read about Large Language Models (LLMs) before. Even if you haven't, you've almost certainly incountered them in the form of ChatGPT or Snapchat's My AI. They are trained by reading massive amounts of text from the internet, from which they learn the statistics of natural language. This makes them really good at a lot of tasks, like question answering and mask-filling (guessing the missing word). Coincidentally, that's exactly what this competition is asking us to do.
To start out, I wanted to get a good baseline. I fine-tuned RoBERTa on the training dataset of New York Times headlines they gave us. Then, I asked it to guess the missing words (fill the masks) on the test dataset from the competition. In order to provide the LLM with as much information as possible, I also gave it the section of the newspaper the aricle appeared in.
The whole idea of this task is to use the images in filling the masks, so I used a state-of-the-art image captioning system (BLIP) to generate captions for each image. Then, I used my fine-tuned RoBERTa model to guess the headline word given the newspaper section and the generated caption. There was no gain in performance!
So what does that mean? The information from current image captioning systems isn't helpful in helping an LLM guess the missing word. This contest was part of FGVC, all about Fine-Grained vision in computing. The captions provided coarse data that didn't improve on the RoBERTa baseline. However, I suspect that large multimodal language models (models that have both vision and capabilites) would perfrom better than my tying together an image model and a language model. If the contest is repeated next year, that's the approach I'll be taking.
Results
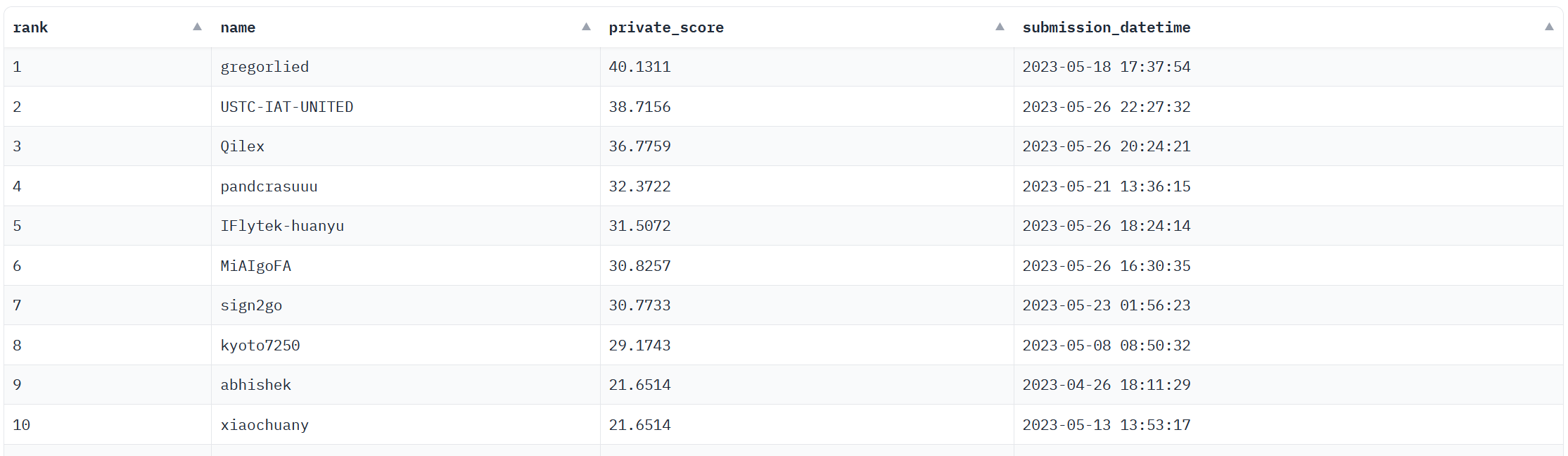
After all that, I got third place in the competition. Top 3 spots were considered winners, and I won some credit to the HuggingFace store. I felt pretty good becasue first place went to a top-ranked Kaggle winner (Kaggle is the premier machine learning contest forum), and second place was a lab from a Chinese university, so I was in good company. It was also a great experince to participate in a full-fledged academic competition.
Want all the Details?
As part of the competition I wrote a technical working paper for the conference. You can read the whole thing here.