Ghost Kitchen
I taught a ghost how to cook using machine learning
Reinforcement Learning
Reinforcement Learning (RL) is a subset of machine learning in which rather than explicitly telling an agent what to do, you help it learn for itself. The agent is given some sort of actions it can take, takes in observations of its environment, and recieves a reward to let it know if it took the right action. Deep RL (RL using neural nets) was very popular through the 2010s, with researchers training agents to walk or play classic videogames. More recently, RL has been used to to teach robots how to interact with the world and even to fine-tune language models like ChatGPT.
As an example, I trained the agent above to play the Atari game Breakout. This agent is given an observation of the last 4 visual frames of the game. At each step of the simulation, the agent can take one of two actions (move right or move left). Finally, it gets a reward. Because the goal of breakout is to last as long as possible, we give it a small positive reward at each timestep. The agent gets a large negative reward for letting the ball past the paddle and losing the game. All of this information (observations, actions, and rewards) are fed into a neural net. As the agent trains, it learns to take correct actions and eventually becomes proficient at playing the game.
Ghost Kitchen
Earlier this year, I did a reinforcement learning course. As part of the course, I trained several agents to do a lot of tasks, but I really wanted to create my own RL environment to teach me more about RL. I wanted to be able to simulate a 3-D environment, so I used Unity. Unity is a game engine that has built-in support for creating reinforcement learning environments and training agents in 3-D space. The underlying physics and rendering engines make it possible to simulate real-world scenarios. I'm already familiar with Unity from creating a video game earlier this year.
Getting Started
You have to walk before you can run, so I decided to start by creating a simple environment with an agent who performs a basic task.
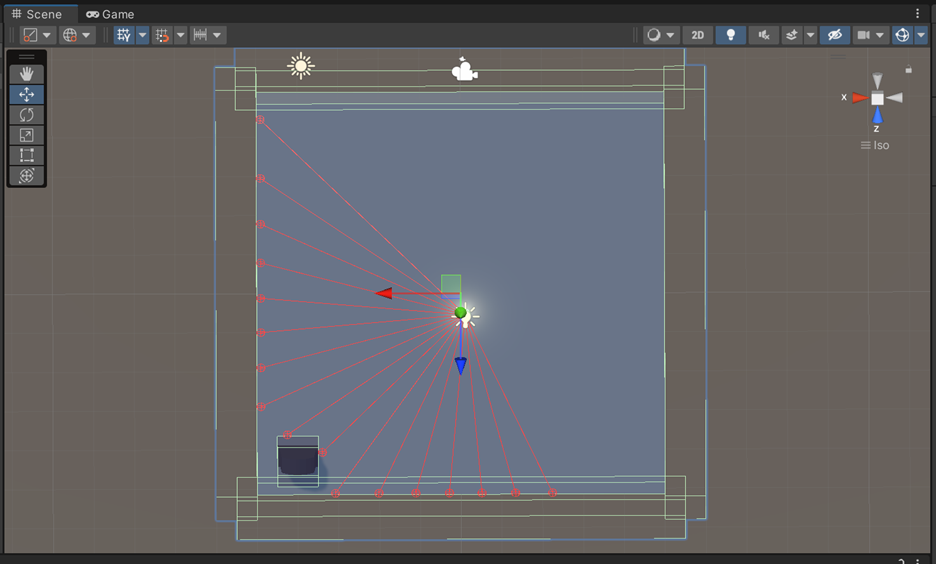
In this task the agent is a little ghost I modeled in blender.
He can take the following actions:
- Rotate Right
- Rotate Left
- Don't Rotate
- Move Forward
- Move Backwards
- Don't Move
His observations are the red rays in the image above. They are how the agent 'sees' the world around him. He can differentiate between the goal and the boundaries where he might fall off the edge.
His rewards are simple. At each timestep, he gets a very small existental penalty (a teeny negative reward) to encourage him to take an action. If he falls off the platform, he gets a large penalty and gets reset. If he hits the goal, he gets a large reward and the goal resets somewhere else for him to find.
After creating the environment, I gave the agent (a little ghost I modeled in blender) a little neural net brain and trained him using SAC, a state-of-the-art reinforcement learning algorithm whose details are beyond the scope of this post.
Creating the Kitchen
I wanted my agent to do something more interesting than simply find a goal, so I decided to give him a multi-part task. The agent knows what two ingredients he needs to bring to the kitchen to 'cook' a dish. For example, he might need to fetch a pumpkin and a pie crust to make pumpkin pie.
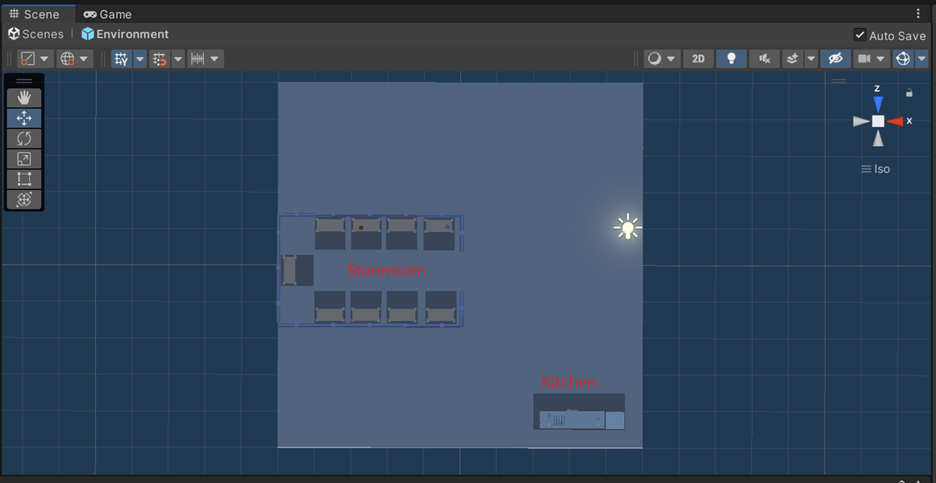
We adapt the ghost from the simple test environment, giving him the ability to pick stuff up and put it down. We also tell him what he's holding, what's in the kitchen, and what ingredients are necessary for the recipe.
Research Question
How can we get an agent to generalize? If we train our agent to cook a bunch of recipes (pumpkin pie, apple pie, and chocolate apples) can it then make chocolate pie?
Training
Training an agent like this is not very straightforward due to something called the sparse reward problem. In order for our agent to get a reward, he has to randomly go to the storeroom, pick up the right thing, take it to the kitchen, go back, grab the right thing again, and take it to the kitchen. Then, he has to realize that doing all of those tasks in order is what is necessary to get a reward. That's a pretty tall order, so how can we make the task easier for our agent?
The answer is task decomposition. Just like you or I might break up a complicated task into smaller subtasks, we can break up the agent's task and supply intermediate rewards for taking steps in the correct direction. I decided to give the agent a small reward every time he picks up an ingredient, and another small reward every time he puts one down in the kitchen.
This led to a well-known problem in reinforcement learning called reward hacking. This is where the agent engages in an incorrect behavior because it can maximize reward that way. In my case, the agent figured out that if he goes really fast, just bringing anything to the kitchen, he gets more rewards than if he were cooking. I had to go back and reconfigure the rewards. I only gave him a reward if he picked up an ingredient still needed in the kitchen.
With only two ingredients on the shelf, our little cook performs the task successfully most of the time. However, it's not clear whether he is just grabbing things at random or he knows what he's doing. In order to figure that out, we fill the storeroom with a bunch of ingredients. At the beginning of each episode, the shelves randomly switch places, so the agent can't just memorize where the ingredients are.
With this difficult task, the agent gets too confused. He just isn't smart enough to learn to not pick up the wrong thing. I tried a lot of tricks to stop him from grabbing the wrong ingredient, but I never made any headway. Finally, I just made him unable to pick up any ingredients that weren't relevant to the current recipe. That worked great.
With this working, I trained him to make caramel apples, chocolate apples, pumpkin pie, and chocolate covered caramels. After all the training, I asked him to make apple pie, and he did, with no problem. That answered my research question about whether the agent would be able to generalize to new tasks.

I had initially thought that to create an agent that could generalize to new tasks, I'd need to train it on a variety of tasks and have it generalize to the last one. It turned out that what the agent ended up needing was underspecification, where instead of learning how to cook many specific things, it just needed to learn to grab two things from the shelves. One hard-coded rule (me not allowing it to grab irrelevant items) was all it took to make a robust, generalizing agent.
With a fully trained agent that's