Tiny Language Models
How small can a Language Model be and still generate coherent text? To find out, I train a pair of Language Models from the ground up.
Language Models
The field of Natural Language Processing (NLP) exploded in 2018 with the introduction of a new technology called Language Models. Before then, neural systems had been used for a variety of tasks like machine language understanding and machine translation, but a huge leap forward was enabled by the invention of a new neural network architecture called the transformer. It was at this time that models like BERT and GPT-1 were invented.
Language Models leverage unsupervised learning (a subset of deep machine learning), training on very large amounts of unlabled text. In this process, the model 'reads' massive amounts of text and learns the dependencies between words. In time, the model learns things about the world, just from the text. For example, after reading millions of stories about people getting caught in the rain or falling in water, it can associate that with the state of being wet. This is called commonsense reasoning, and it is an example of an emergent ebilitiy.
Emergent abilities are abilities that a model gains despite never being explicitly trained on a task. For example, GPT-3 is pretty good at basic addition and multiplication simply because it's seen so many examples on the internet even though it was never 'taught' math. Emergent abilities are usually only seen on models of a certain size. (Pretty large models)
Language Model Sizes
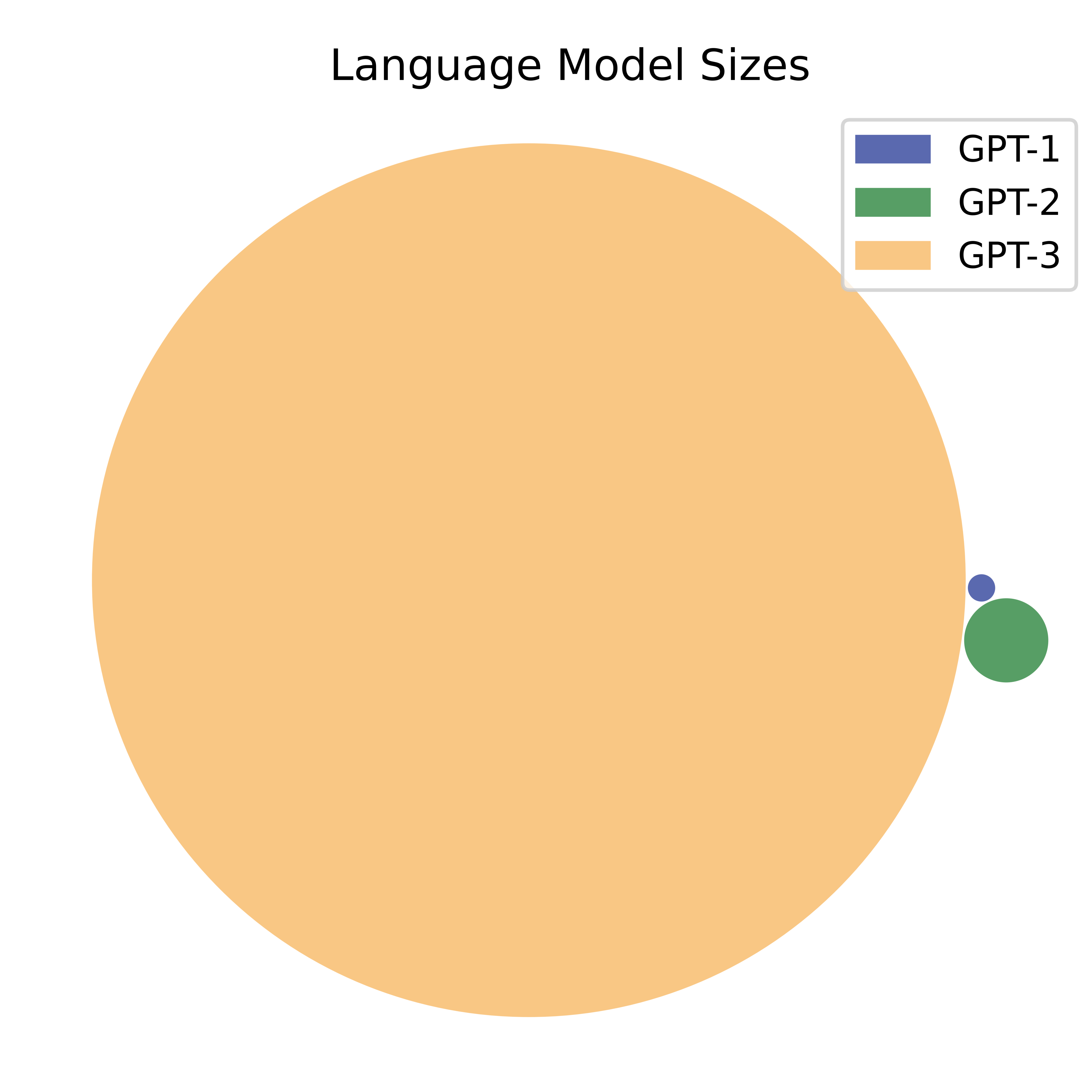
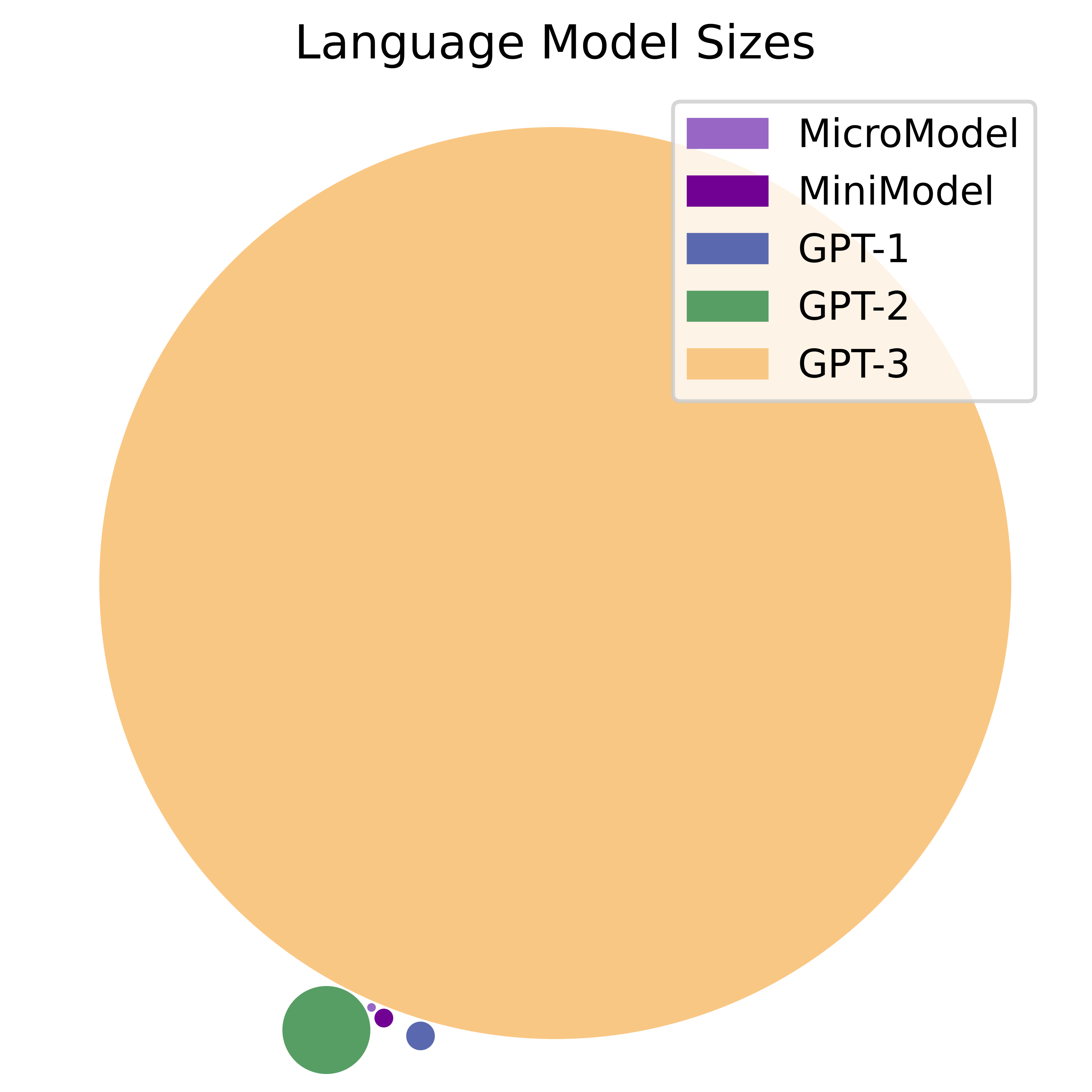
Early Language Models like BERT and GPT-1 were very small compared to modern Language Models, both in terms of model size and amount of training data. We use parameter count as a measure of model size. Parameters are the weights a model learns while it trains. More parameters allow a model to learn more.
- GPT-1 has 120 Million parameters, and was trained on a very small amount of text (about 7000 books).
- GPT-2 has 1.5 Billion parameters, and was trained on a dataset 10X larger (40GB of text from 45 Million webpages).
- GPT-3 has 175 Billion parameters, and was trained on 45TB of text, including Wikipedia, 400 Billion words from webpages, and 60 Billion words from books.
- ChatGPT and GPT-4 have an undisclosed number of parameters, but we can infer they are much larger than GPT-3 and are trained on a lot more data.
Why do the models keep getting bigger? It turns out that bigger models do better at pretty much everything, from reasoning abilities to text coherence.
Let's compare the completions of GPT 1, 2, and 3, on the same prompt:
Sam fell down and
GPT-1
Sam fell down and i was forced to do it, too. "
" you okay? "
she nodded. " how did your date go? "
" fine - for now. why... do you want to dance? "
GPT-2
Sam fell down and fell to the ground.
"I'm sorry, I'm sorry,"
GPT-3
Sam fell down and broke his leg
If Sam falls and breaks his leg, he should be taken to a hospital to receive medical treatment and a diagnosis. The doctor will be able to review the injury and determine what course of action is best, which may include surgery or physical therapy.
We can see that GPT-1 just continues with a random snippet of dialog that has nothing to do with the prompt. GPT-2 gets confused, and has sam fall down twice in a row, and then someone says they're sorry. This is more relevant, but still not ideal behavior. Neither of these are very good. GPT-3, which is much bigger, has a reasonable understanding of falling (you can break your leg from it.) Contrast this with GPT-2 not understanding that you don't fall down twice in a row. GPT-3 also suggests what Sam should do, and gives sound advice.
This illustrates that commonsense reasoning ability increases with model size. We also see more coherent text as model size increases.
Because Language Models gain capabilities as model size and training data scale up, the trend in NLP research over the last 5 years has been to train bigger models on larger datasets. While this results in truly impressive models like ChatGPT, these models are also prohibitively large. They require too much disk space to comfortably fit on most consumer computers, and are too large to be loaded into RAM on most computers. The only way for most people to use these Large Language Models is to access someone else's model running elsewhere via the internet. This can create problems. What if you want a personalized model? What if you want to use a model offline? What if you don't want to pay OpenAI?
Because of this, there's been increasing interest in creating smaller language models that have sufficient capabilities to perfom one or two tasks. Not every model needs ChatGPT-level abilities in all domains. How small of a model can we train that still generates coherent text? That's what we want to figure out.
The TinyStories Dataset
An interesting paper I read earlier this year presented the TinyStories dataset. The idea behind the paper is that you can train a really small model (smaller even than GPT-1) that performs pretty well on one task as long as the model is trained on high-quality, in-domain data. In this case, TinyStories is a set of very short stories with a targer audience of a 3 or 4-year-old child.
The TinyStories dataset contains around 5 million stories like the one pictured above. Each of them are short, easy to understand, and follow a simple narrative structure. In all, the dataset is less than 4GB of text.
The paper claims that training small models on domain-restricted data allows them to perfom much better than would be expected. Based on the examples above, we wouldn't expect models smaller than GPT-1 to be able to generate coherent text, but the paper shows impressive results.
Training the Models
I decided to train two very small models, a 4.6 Million parameter MicroModel and a 47 Million parameter MiniModel. The first one is 1/20th the size of GPT-1 and the second is less than half the size of GPT-1.
As a base for my code, I used Andrej Karpathy's MinGPT, a simple implementation of the Transformer. It takes in some inputs (a sequence of encoded words), and learns to predict an output (the next word in the sequence). Text generation models are as simple as that!
Neural Nets
Neural nets can be pretty intimidating. It may be helpful to think of them as advanced function approximators. If you consider whatever you're trying to learn with a neural net, there's some natural distribution you want to model. That distribution may be very complex, but it can usually be approximated. We approximate that function using a neural net. You can think of neural nets as doing a lot of complex math very quickly. The neural net has a bunch of weights (or parameters), which are updated as the model trains. The training updates those weights until the neural net is a good at approximating the data.
Tokenization
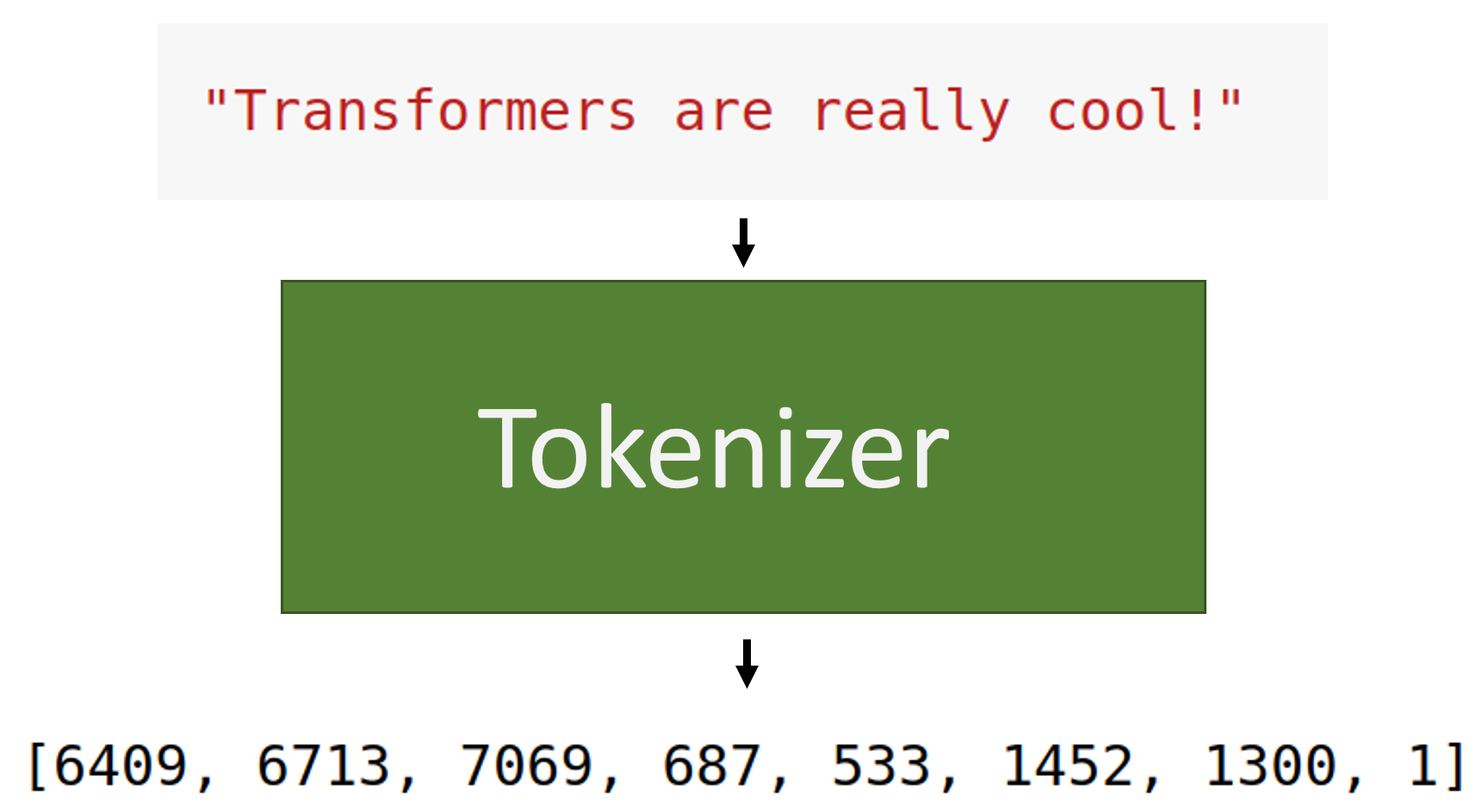
If a neural net just does math, how do we give it text?
We need something called a tokenizer, which takes the text and turn it into numbers.
It's not necessary to reinvent the wheel here, though.
We take the original GPT-2 tokenizer and train it on the most frequent 10000 words from our dataset of stories.
It learns a function to turn words into numbers to feed into the neural net.
Then, the neural net can do math on the numbers, and output new numbers which represent the text completion.
We can push the output backwards through the tokenizer to turn the output from the neural net into words.
(The tokenizer is available here if you're interested.)
To create the training data for our model, we take our 5 million stories and stick a special token at the end of each one that looks like this: <|endofsequence|>. The model learns (in our case) that when it sees an end of sequence token, the story is over. Then, after the end of sequence token, it knows to start a new story.
When we train the model, we pass it two things: a sequence of tokens (text we turned into numbers), and the next token (word) in the sequence. The model learns dependencies between words in the sequence, and tries to predict what the next word should be. Then we reveal what the next word was, and have the model update its weights to better match its guess to the true answer. As this training goes on, our models outputs our brought in line wiht the distribution of the data (in our case, simple English stories).
We repeat this process until our model has read all 5 million stories in our dataset. Using the supercomputer at BYU (I'm glad I have access to that now), we can train the 4.7 Million parameter MicroModel in about 40 minutes. The 47 Million parameter MiniModel needs about 6 hours to fully train, but that's still very quick. It would take the average American adult about 6 years with no breaks to read all 5 million stories.
Model Performance
Before we look at the model performance, let's reiterate how small these models are and how little data they've seen. Neuroscientists estimate that the human brain has 100 Trillion connections. (100,000,000,000,000) Our models have 47 million (47,000,000) and 4.7 million (4,700,000) parameters, making them much smaller than any GPT model. The only things our models know about the world they know from reading a bunch of very short children's stories. We wouldn't necessarily expect good performance based on that.
We can start evaluating our trained models starting with our prompt from earlier.
MicroModel
Sam fell down and started to cry. Sue heard the cry and came running to help.
MiniModel
Sam fell down and bumped his head. It hurts. He started to cry.
Lily ran to him and helped him up. She said "Sam, I'm sorry, I didn't mean to hurt you. Are you okay?"
These look great! Both tiny models perform much better than GPT-2, in spite of being 30 (or 300) times smaller. Let's try one more prompt completion.
Sam played outside in the snow and got very cold so he went home and
GPT-1
Sam played outside in the snow and got very cold so he went home and had a short nap before dinner.
GPT-2
Sam played outside in the snow and got very cold so he went home and got a cold shower.
GPT-3
Sam played outside in the snow and got very cold so he went home and drank a hot cup of cocoa.
MicroModel
Sam played outside in the snow and got very cold so he went home and drank warm water.
MiniModel
Sam played outside in the snow and got very cold so he went home and put on his hot coat.
Once again, we see that GPT-1 and 2 don't really do things that would warm you up. GPT-3, which is huge, perfoms well (as we'd expect). Notably, both the Mini and Micro models suggest things that would help Sam warm up (drinking a warm drink or putting on a hot coat).
Now let's look at some examples of whole stories generated by these models.
Examples
MicroModel
Once upon a time, there was a little boy named Timmy. Timmy loved to play outside in the sun. He would run and jump and slide on the slide all day long. One day, Timmy saw a leak in the ground. The water fountain was important and shiny. Timmy wanted to help the water fix the leak, but he didn't know that the water at school were dangerous. So, Timmy went inside to see the shooting can out. His mom explained that the leak was still good and made Timmy sad. They decided to change the leak and take care of it. Timmy watered the leak every day and soon the leak was gone again. The people in the town looked at the leak and were surprised, but they were happy. They helped Timmy fix the leak and Timmy kept playing until the leak went out. It was a success!
One day, Tim and Sam were playing in the yard. They liked to play with a big staff. They used their long stick to split red balls and dirt each cats.
As they played, a little dog came out of the bushes. Tim and Sam were scared and did not want the dog to play. Then, something unexpected happened. The dog started to bark and wag its tail! Tim and Sam looked at each other and talked.
bicy them something unexpected happened. To their surprise, the cat stopped barking and looked at all the animals. Tim and Sam felt happy because they could play with the dog and the sweetheart. They played together and had lots of fun. From that day on, Tim and Sam were the best of friends.
We can see that the 4.7 million parameter model isn't amazing at writing whole stories. It is interesting to see what the model has learned. In the first story, the model clearly knows that a leak is bad and has to do with water. In the second, it knows that a staff is a long stick, and gets cats and dogs a little mixed up, but that's good! Cats and dogs are pretty similar.
MiniModel
One day, a little boy named Sam went for a walk. He wanted to rain because it made the ground wet and the ground was icy. While walking, he heard a tiny voice say, "Help me, please!"
Sam looked around and saw a small bird. The bird was stuck in a crack in a tree. "Don't worry little bird, I will help you," Sam said. He climbed the tree and helped the bird get out.
"Thank you so much!" the bird chirped. Sam felt happy that he could help his new friend. They both walked back home together, talking and laughing,
Once upon a time, there was a little boy named Tim. Tim loved to go on walks. One day, they went to the park to play. Tim was very happy.
At the park, Tim saw a butterfly. The butterfly was so pretty, with it made Tim feel happy too. The butterfly jumped on Tim's shoulder and made him feel better. They played together and had lots of fun.
As the sun went down, Tim and butterfly went home. They said goodbye and went to sleep. Tim knew it was time to go home, but he couldn't wait to see the butterfly again. The next day, Tim went back to the park and played with his friends again
One day, a little boy named Tim went to play outside. He had a big boat with a sail. Tim loved to sail on the water with his friends. He was very good at it. He felt like a pilot.
One day, Tim saw a big hill. He wanted to climb it, but he was scared. He thought his friend would not believe him. So, he looked around and found a small box. He opened it and saw a toy bear inside. He was a little scared, but he thought the bear would be okay.
Tim took the toy bear to his friend and showed it to his friend. His friend believed him, and they played with the toy bear all day. They had so much fun, they became good friends. From that day on, Tim was not scared of the big hill anymore.
These stories are pretty good! The models are so small they can have trouble learning long-term dependencies, which means they can forget things from sentence to sentence. Sometimes, the plot will take a sharp turn in the middle. In spite of that, the stories are pretty coherent and make a fair amount of sense.
Conclusion
The fact that models this small can produce pretty good text (especially on the sentence level) has exciting implications for the future of language models. With small, performant models, we could create virtual assistants tailored to a person available for offline use. Even better, we could use tiny models small enough to live on a phone to create good autocomplete!