Multilingual Pretraining for Machine Translation
The data that language models are pretrained effects the models' downstream performance. I test how pretraining on multiple languages helps or hinders machine translation.
Note
This post is about work I did back in 2022 while I was applying to PhD programs. I did this research for a student conference in linguistics that I didn't end up getting to attend. This blog post has been on my to-do list since then.
Machine Translation
Machine translation seems like a straightforward task: take in an input sentence in one language and output the translation in a different language. In reality, it's pretty complicated. This is because there's not really a one-to-one mapping from sentence to sentence, as there are a lot of different ways to communicate the same idea.
Consider the following scenario: You're walking outside on a day that looks like this:

You come inside and your friend asks, "How's the weather?"
You might truthfully respond several ways:
- "It's nice out."
- "Pretty sunny."
- "Warm, with a light breeze."
- "Hotter than yesterday."
These are all ways of communicating the same idea: that it's a nice, sunny day. Is one of them better than the others? Probably not. It really just depends on how you're feeling and what exactly you wish to communicate.
Since none of these responses is more correct than the others, which one would we want to teach a machine? If none is best, which would we use to evaluate whether output translation is correct?
These issues make machine translation difficult.
Machine Translation with Large Language Models
Large Language Models (LLMs) are the state-of-the-art technology for most language tasks, and machine translation is no exception. I write a lot about LLMs, so this may be review. Language models are pretrained on massive amounts of data from the internet. This pretraining helps models learn the structure of language: grammar, syntax, and semantics. This is also how models gain world knowledge. Most models have see trillions of tokens (words) by the time they are done training.
As a consequence of this paradigm, changing the content of the pretraining data changes a model's knowledge and abilities.
Fine Tuning
Pretrained models know a lot about language and about the world. However, they still need to be fine tuned on in-domain examples. If you show a pretrained language model a bunch of pairs of sentences in a source language and a target language, the model can learn to translate between the two languages. The model is able to leverage the knowledge gained during the pretraining step when it comes time to translate. This can help with the issue described above where multiple sentences mean roughly the same thing. Since pretraining teaches the model synonyms, the model can use that knowledge while translating.
Experiment
The research question is simple: If we pre-train on several languages (not including the target language), how does that effect translation performance after fine tuning?
For this project we use sequence-to-sequence (seq2seq) langugage models. These models are sometimes called encoder-decoder models and they differ in architecture from autoregressive (decoder-only) models like ChatGPT. The main difference is that encoder-decoder models map an input to an output whereas decoder-only models just create an output (optionally conditioned on previous text). These probably seem pretty similar to you. From a user perspective, these processes are pretty much the same. The internal differences are beyond the scope of this post. Suffice it to say that the internal structure that maps inputs to outputs makes sequence-to-sequence models ideal for machine translation.
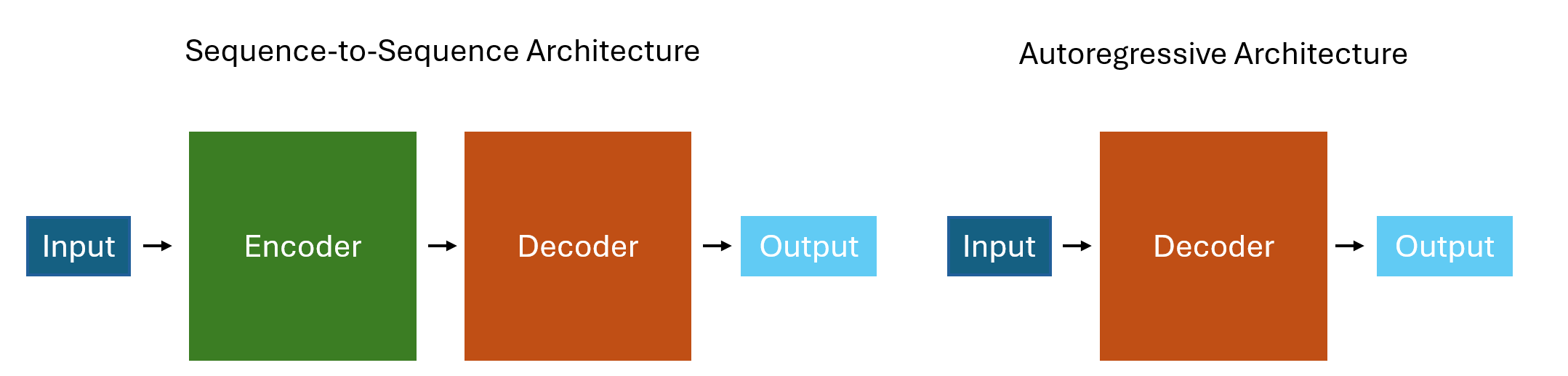
I did this experiment using T5 and mT5, two seq2seq models from Google. The main difference between the two models is that T5 is trained primarily on English text. MT5, on the other hand, is trained on text from over 100 languages. Both of these models are available in checkpoints of various sizes (small, base, and large). These pretrained checkpoints follow predictable scaling laws, with model performance improving as model size increases.
For this experiment, I used the Modern English to Middle English dataset I created for my Middle English Translator containing about 58,000 sentence pairs. I trained the small, medium, and large checkpoints of both T5 and mT5 on the same dataset using an A100 GPU. In simple terms, this involves taking the pretrained checkpoints and trying to teach them how to translate Modern English to Middle English by showing them the 58,000 examples.
Middle English
It is important to understand the fine-tuning data to better understand the model. In order to understand the data, we need to understand the language it's in. Middle English is a variety of English spoken after 1066, when England was invaded by French-speaking Normans. If you had to read anything by Geoffrey Chaucer in high school, you've read some Middle English. It was spoken until the 1500s, when it morphed into Early Modern Engilsh (the language of Shakespeare). The Norman invaders introduced a lot of French into English (in fact, about 1/3 of English words are borrowed from French thanks to this invasion.)
Evaluation Metric
Evaluating machine translation is hard. We touched on this earlier, but the fact that different sentences can mean the same thing causes issues when judging translations. Which one is right? If we have a bunch of sentence pairs to test on, we can hand the model a sentence and see whether the model generates the same sentence as our test pair. That's not ideal because our model could produce a great translation different from our test translation and we'd give it a bad score. To get around this, machine translation researchers have created a metric, BLEU, that uses a few algorithms to measure the 'goodness' of a translation. While BLEU isn't perfect, it is the industry standard. More recently, BLEU has been improved. I used the updated version of BLEU, sacreBLEU, to evaluate the finetuned models.
Results
After training the models and evaluating them, it's clear that multilingual pretraining helps multiple sizes of model perform better on the task of translating English to Middle English. The benefit of multilingual pretraining is roughly the same as scaling up one model checkpoint size. For example, mT5-Small is about as good as T5-Base. This means that multilingual pretraining is a great way to get more bang for your model size buck. Either you can use a smaller, more efficient model for equal performance or you can use a larger model with multilingual pretraining to improve model performance.
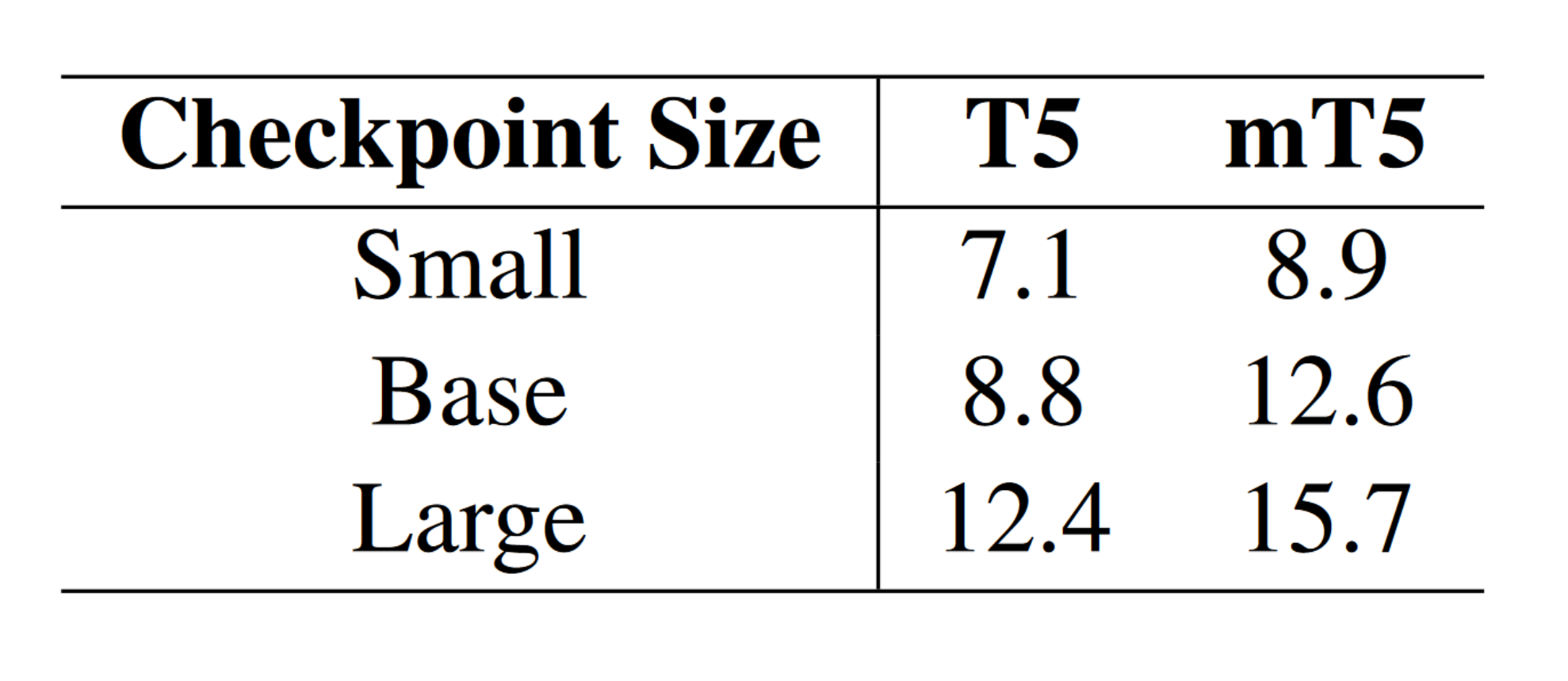
Why does this work? Middle English has some different rules from Modern English. These different rules might be reflected in the mT5 training data. Even though mT5 was never trained on Middle English, the grammar rules from the other 100 pretraining languages probably helped mT5 be better at generalizing to new grammatical structures. We know this happened to some degree because one of the languages that mT5 was trained on was French. French influence from the Norman invasion was responsible for many of Middle English's different rules and words. MT5's French pretraining probably accounts for some of the increased ability to model Middle English.
Discussion
This project might seem a little silly. Who cares if multilingual pretraining is helpful when we translate into Middle English? Nobody even speaks that anymore.
The results are important because they show a generalizable principle, that multilingual pretraining can help a model on downstream translation tasks. This is particularly valuable in the case of low-resource languages, languages with small amounts of written data. Speakers of these languages often struggle to access internet content and machine translation provides a bridge whereby they can take advantage of the web. Although there may not be much training data in these languages, I've shown that multilingual pretraining can improve language models' translation skills. This has the potential to help speakers of low-resource language to acces higher quality machine translation tools.
I wrote a short academic report on this experiment which you can read here.