Testing Dall-e Mini
Dall-e Mini has taken the internet by storm. Its capabilities are impressive, but what are its limitations?
Large Denoising Diffusion Models
This year has been extremely exciting in the world of text-to-image generation. Openai's Dall-e 2 made waves, closely followed by
Google's Imagen. Both of these models can produce amazingly realistic images of almost anything in a variety of styles. Unfortunately, they are also completely unavailable to the general public.
On the one hand, I get it. I understand that giving anyone in the world the power to draw a picture of anything is unprecedented and probably has unforseen consequences for society. On the other hand, is giving that power to a few already powerful corporations any better?
That's not what we're here to talk about today, though. Today we're talking about Dall-e mini, Boris Dayma's attempt to democratize this technology. (Dall-e Mini is not a diffusion model, but we're not going to dwell on that here.)
While significantly less powerful than the big companies' models, dall-e mini is an amazing feat, and free for anyone to use. Let's dive in.
If you're smarter than me maybe you'll understand this 2020 paper introducing them.
This blog post from huggingface is easier to understand, but still requires some technical know-how.
I'm not an image guy, I'm a text guy, so I don't fully understand how these models work. However, we don't need to. Just like you don't need to understand the nuances of the internal combustion engine to drive a car, we can 'drive' these models without fully understanding the underlying mechanism.
Prompt Engineering: How to 'Drive' the Model
As large models have become smarter, they have gained the capability to accept instructions in natural language. You can prompt GPT-3 to 'Tell me a story about two happy frogs' and it'll write a nice little piece for you.
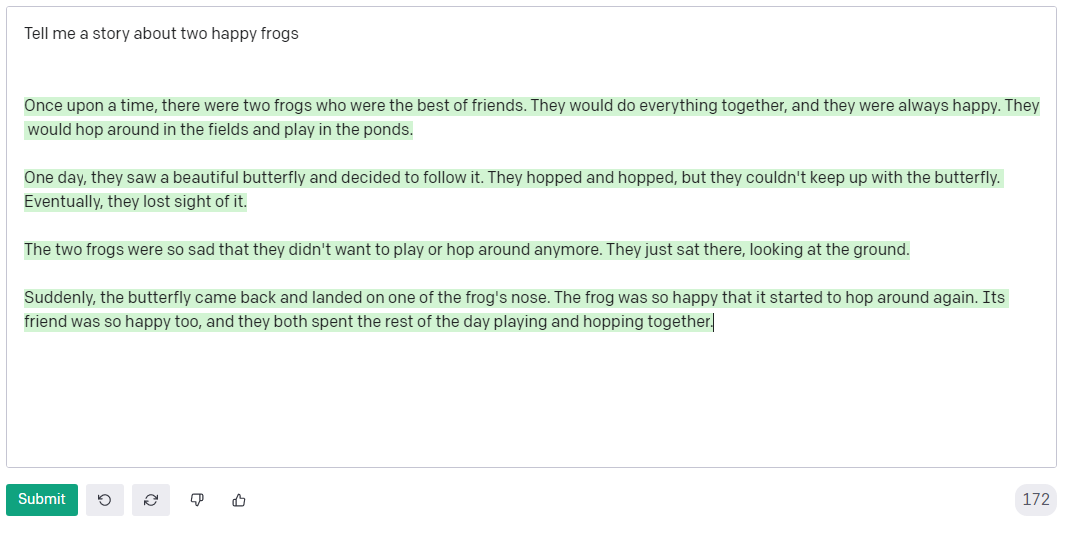
That didn't take any special ability, I just had to ask. However, changing the prompts can drastically improve performance on certain tasks. For example, asking GPT-3 to 'explain your reasoning' results in much more in-depth answers.
If we ask GPT-3 "How many trolls are in the forest?" it responds:
There are an unknown number of trolls in the forest.
However, if we ask "How many trolls are in the forest? Explain your reasoning." we get :
There is no set answer to this question as the number of trolls in the forest can vary depending on the story. However, it is typically assumed that there are at least a few trolls living in the forest, as they are often depicted as inhabiting dark and dangerous places.
Prompt Engineering, or learning to ask the right question, is just as important for image generation models as it is for text-generation ones.
Testing Dall-e Mini
People have been playing around with this model for weeks, and it seems like the formula for generating a funny and successful series of images is the following:
- Take a well-known character
- Put them in an unlikely context
If I remember correctly from my Linguistics undergraduate days, this formula is successful because of its juxtaposition of pragmatic frames.
So let's do that. I decided to try and put two well-known characters in different spots.
- The Teletubbies in early Christian art
- Tony Soprano in a video game
Teletubbies in Early Christian Art
The first thing I decided to try was asking for traditional scenes from Christian art. I tried 'Teletubbies Pietà', 'Teletubbies Annunciation', 'Teletubbies Stations of the Cross', etc. All to no avail.
These were all largely unsuccessful. It seems like dall-e mini can't abstract the traditional composition of these images and replace the characters with teletubbies.
So the next thing I decided to try was putting the Teletubbies in the style of several artists famous for Christain paintings. This had aobut a 50% success rate. 'painted by Raphael' and 'painted by Michelangelo' didn't change the style of the images, whereas 'painted by Caravaggio' and 'painted by El Greco' did a decent job of stylistic transfer.
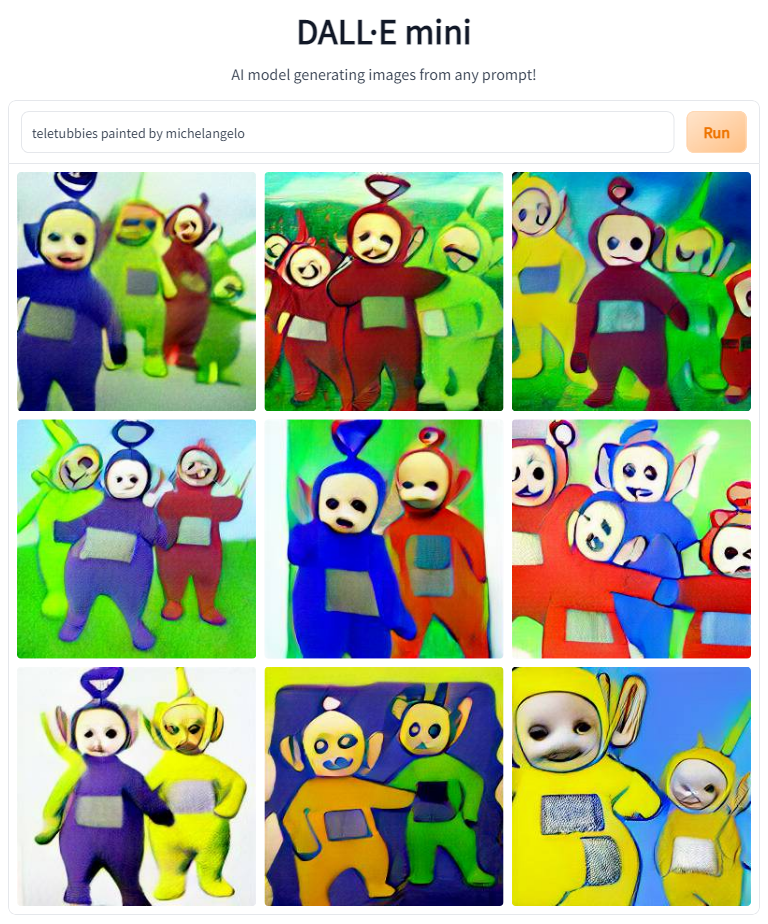
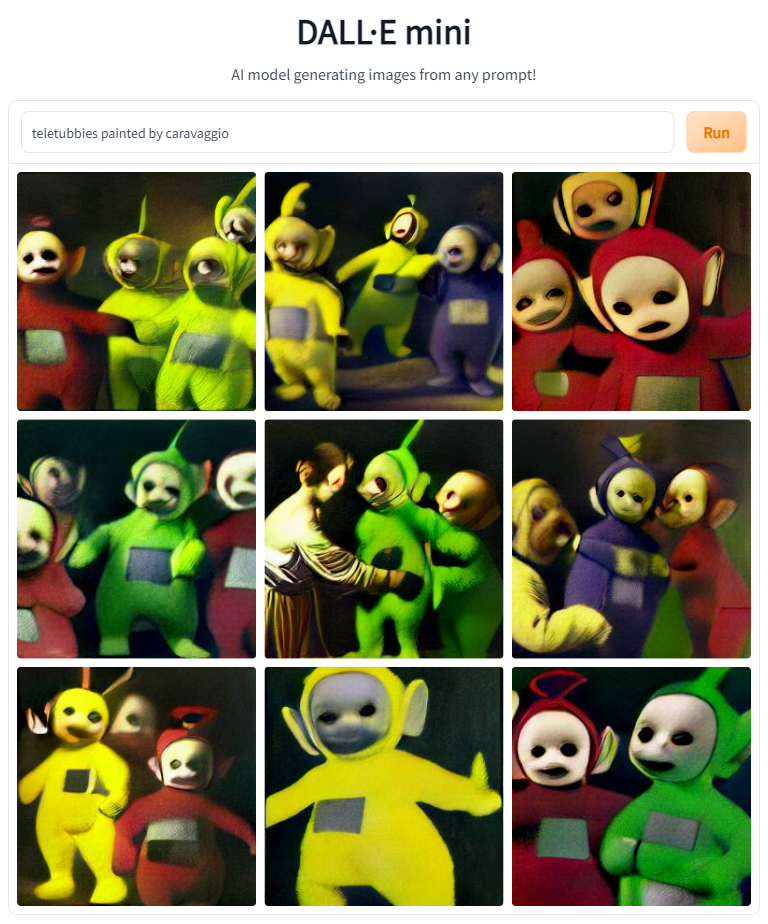
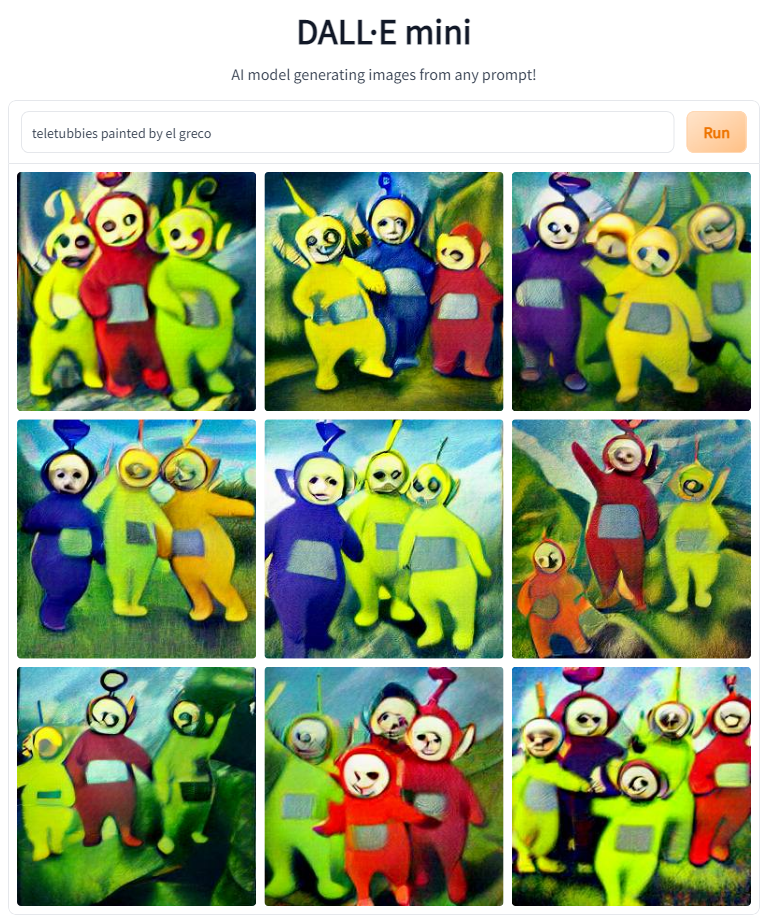
At this point, it became clear that artist credits could transfer style, but not content. This makes sense.
Even though most of El Greco's paintings are religious in nature, they don't all depict the same scenes.
The model picks up on some of his distinct style, which is common to all of his paintings.
I decided to broaden my search to different genres of early Christian art.
Some of the prompts I came up with were 'Orthodox Icon' and 'Byzantine Art', and I tried appending other words that could help cue the model into knowing what I was hoping for.
Since most Tryptiches were of early Christain art, I thought that 'Tryptich' could help, and I tried 'Mosaic' (a popular medium) as well.
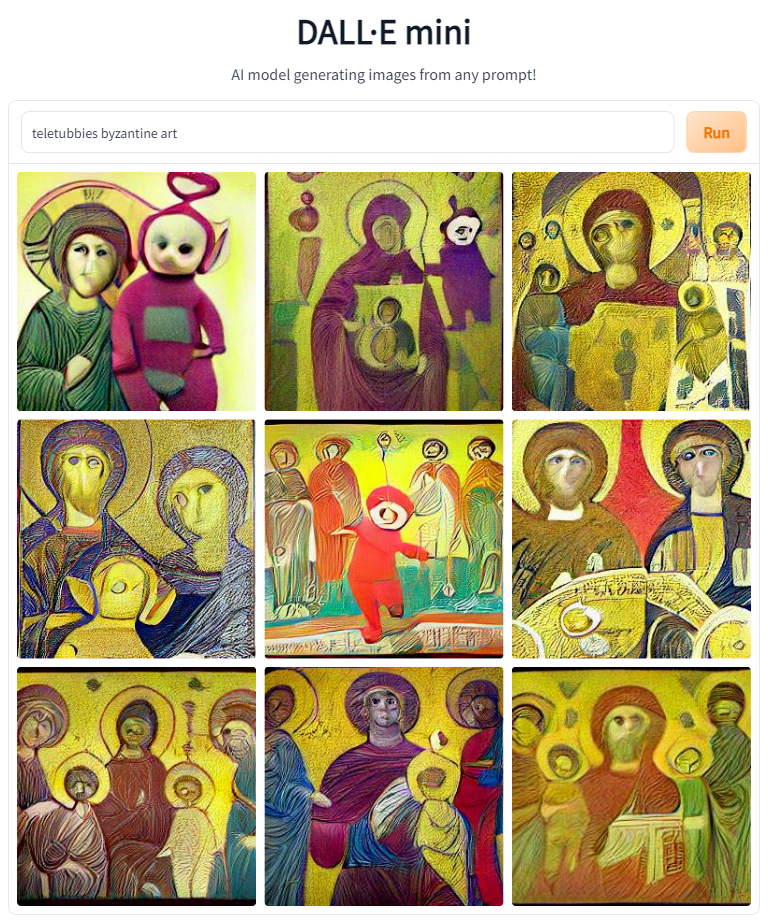
Given the success of the word Tryptich, I decided to experiment with other items often found exclusively in Christain art contexts. I decided to try creating common Christian items that often depict images. 'Stained Glass' and 'Votive Candles' both seemed like safe bets.
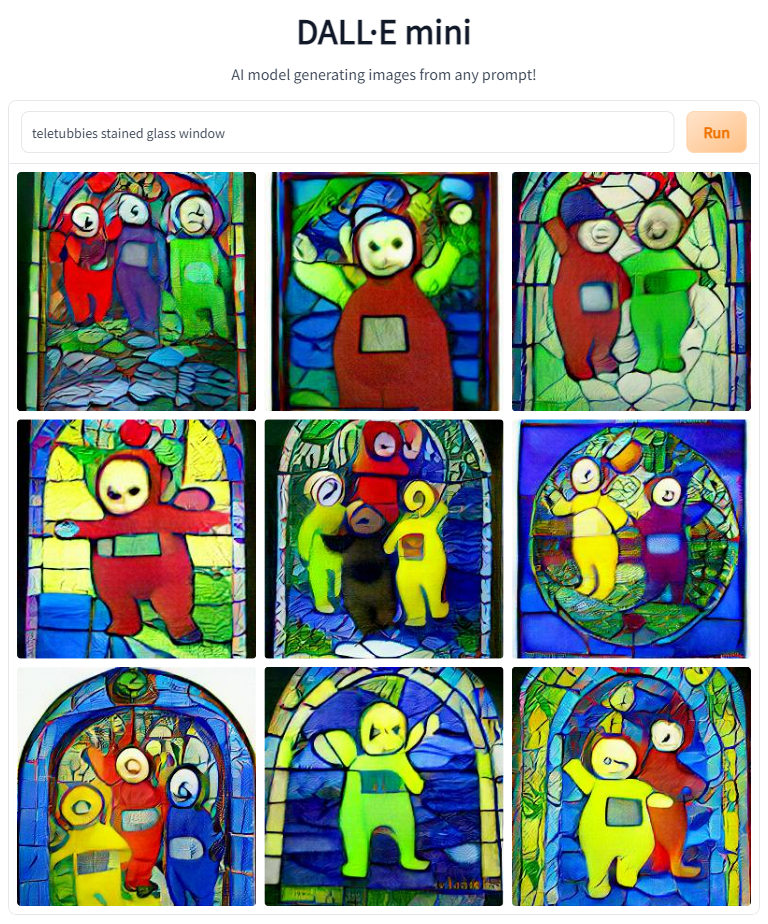
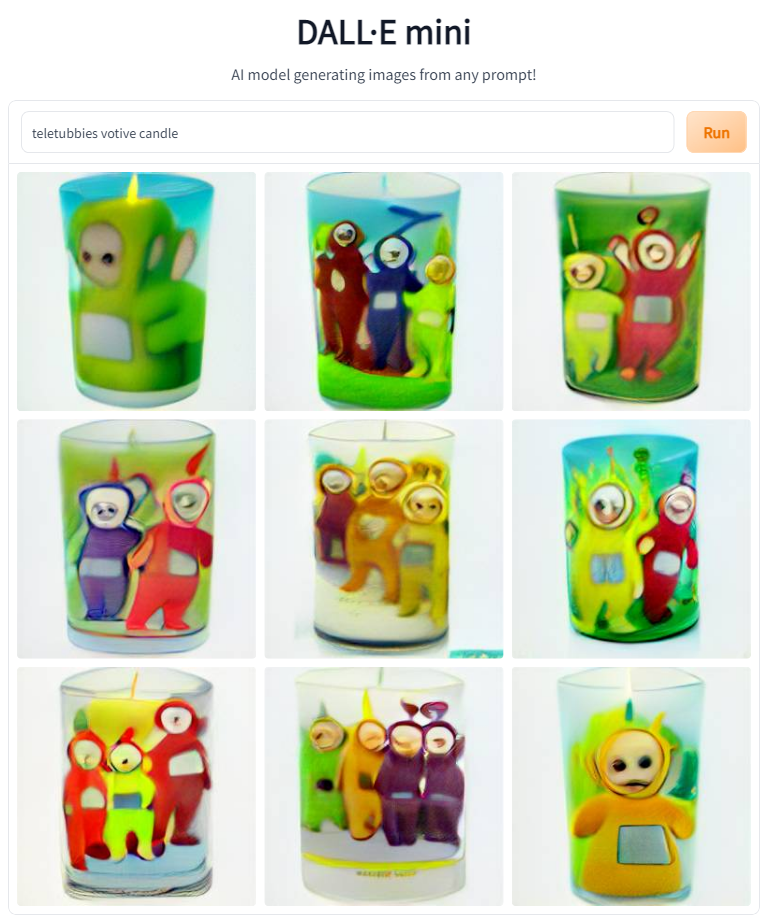
What did we learn from this? Artist names can help transfer style, but not content. Giving the subject a context (Orthodox Icon, Stained Glass) was much more effective at melding two distinct things. Interestingly, the context can have more strength than the characters (like with Byzantine Art), or the characters can overpower the rest of the prompt (like with The Annunciation).
Tony Soprano in Video Games
The Sopranos is widely considered one of the greatest TV shows of all time, taking the #1 spot in Rolling Stone's 2016 rankings. Its viewership was extremely high while it was on the air, and even now more than 15 years later, The Sopranos is one of the most popular shows on HBO Max.
While the sopranos did get a spinoff video game in 2006, it was not well-recieved. So let's try and put Tony Soprano (the titular character) in some well-known video games.
I'm not too much of a gamer, so to get started I did a google search for some of the most popular video games of all time.
I haven't played most of the games on the list, so I chose games I've at least heard about so I could recognize whether the pictures capture the game.
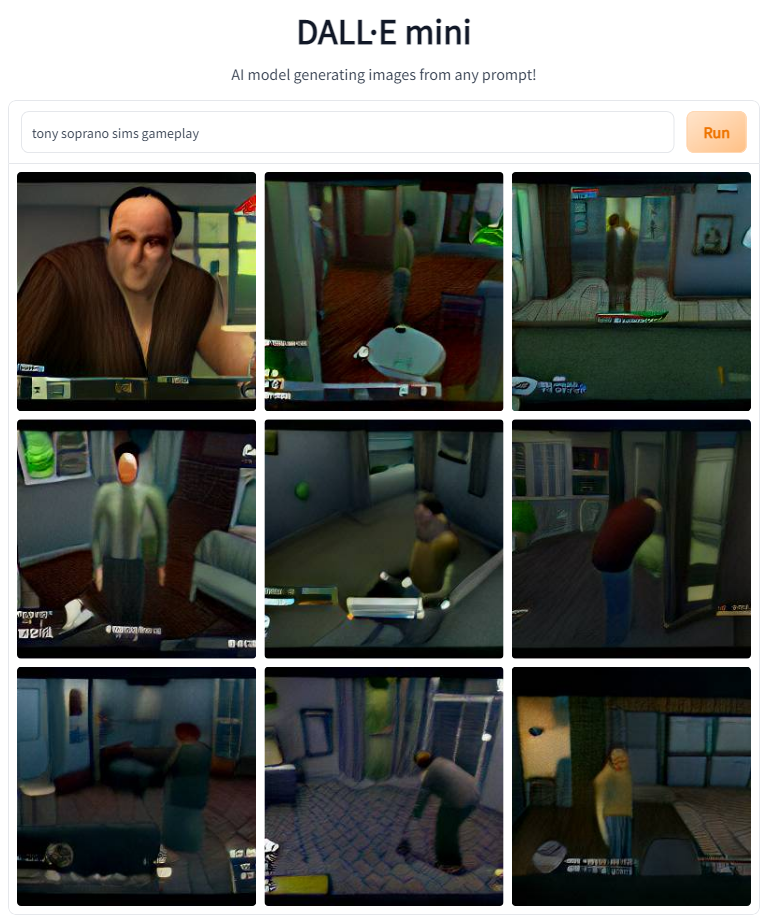
My prompt engineering started in a very basic fashion, with 'Tony Soprano ______'. Sometimes it worked pretty well, but sometimes I needed to tack the word 'gameplay' on the end.
Let's look at the results. We'll start with the earliest games on the list, Doom and Half-Life.
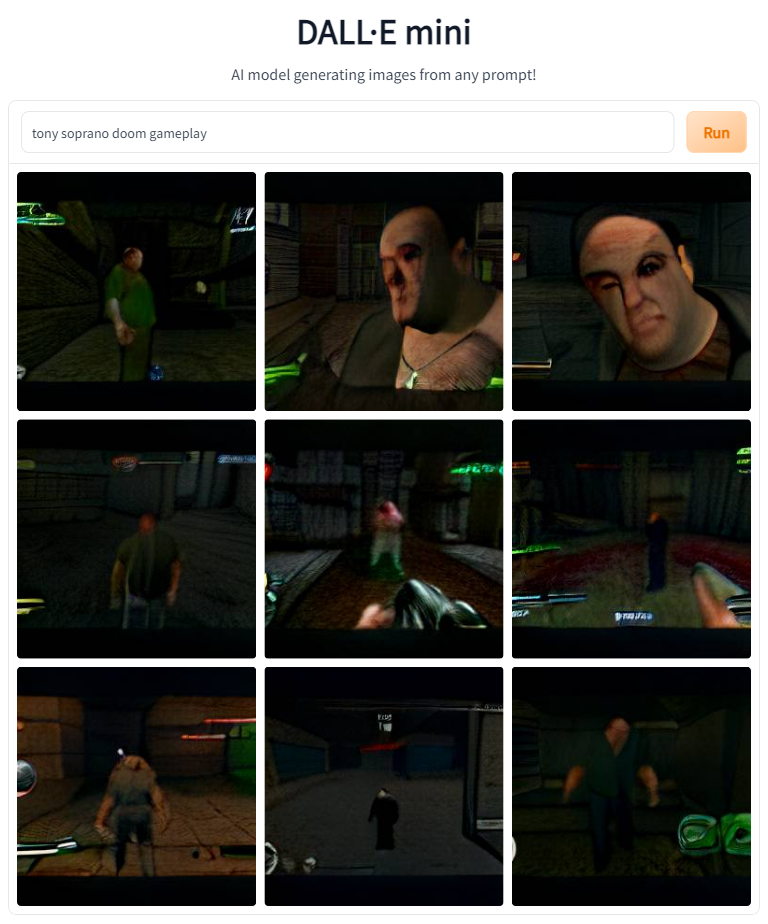
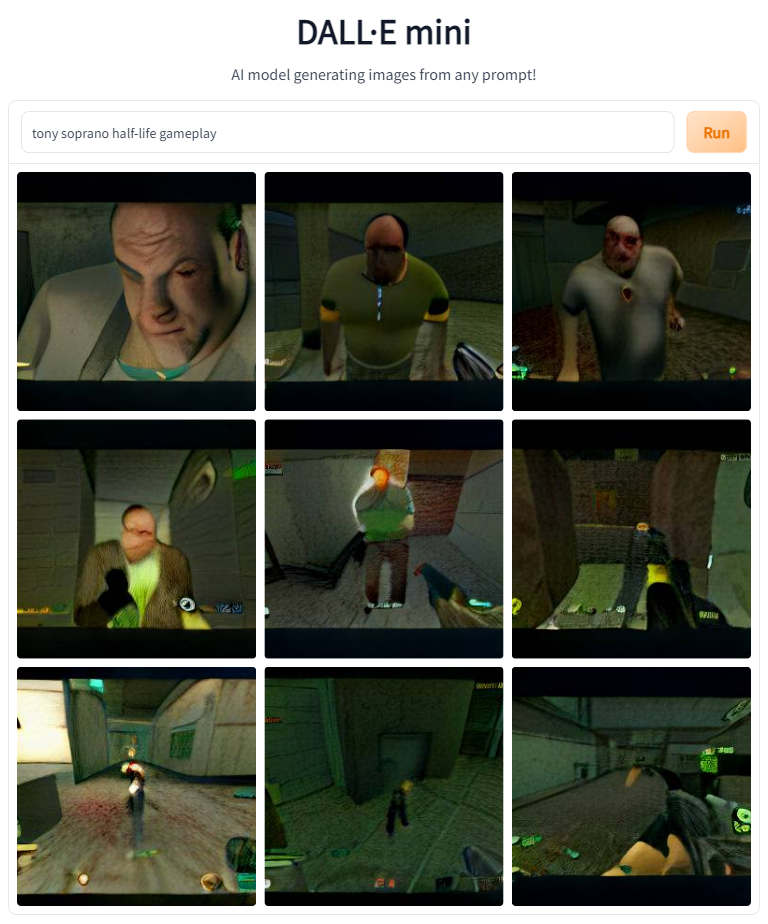
We're off to a great start. Both of these images feature someone who looks like Tony Soprano and blocky 20-year-old graphics. The Doom shot also features the series's signature dark environments.
Next, I decided to embrace one of the biggest franchises from my childhood, Pokémon.
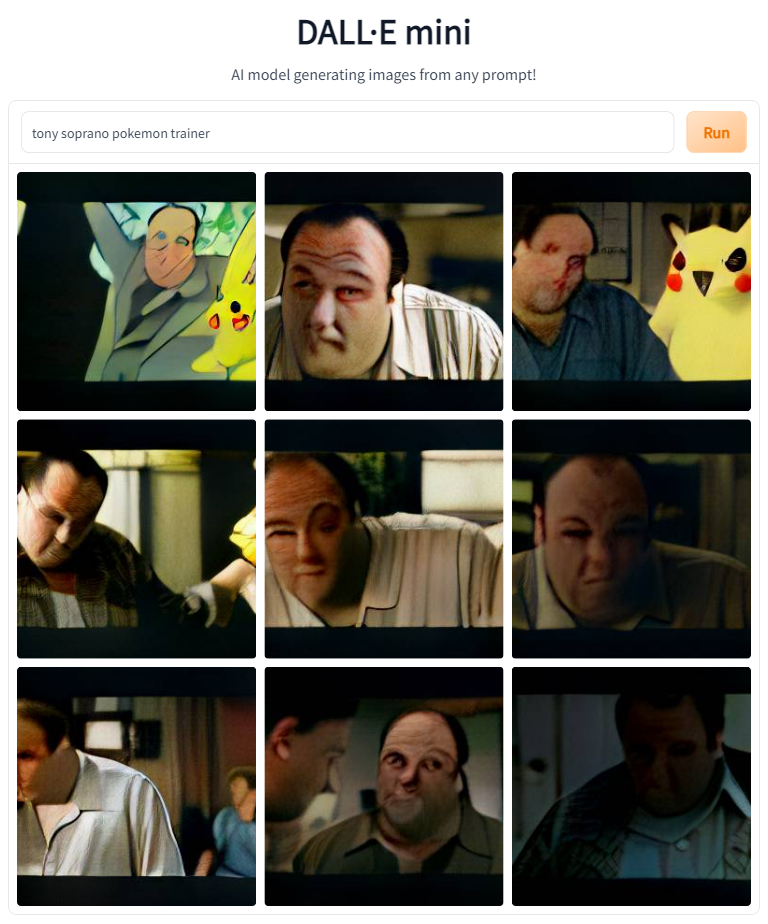
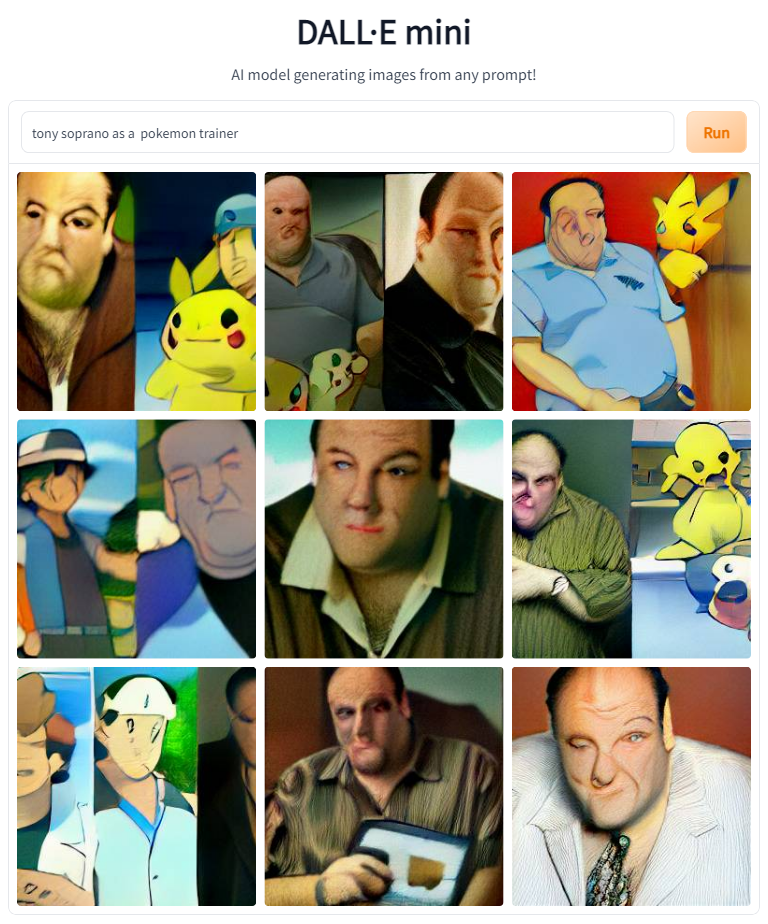
So from this it seems like for the model to be successful we need to put Tony in the game, not just style him as a character from the game.
Since Fortnite does crossovers with people from outside the game all of the time, I figured the model would have some idea how to translate a real-world person into the game.
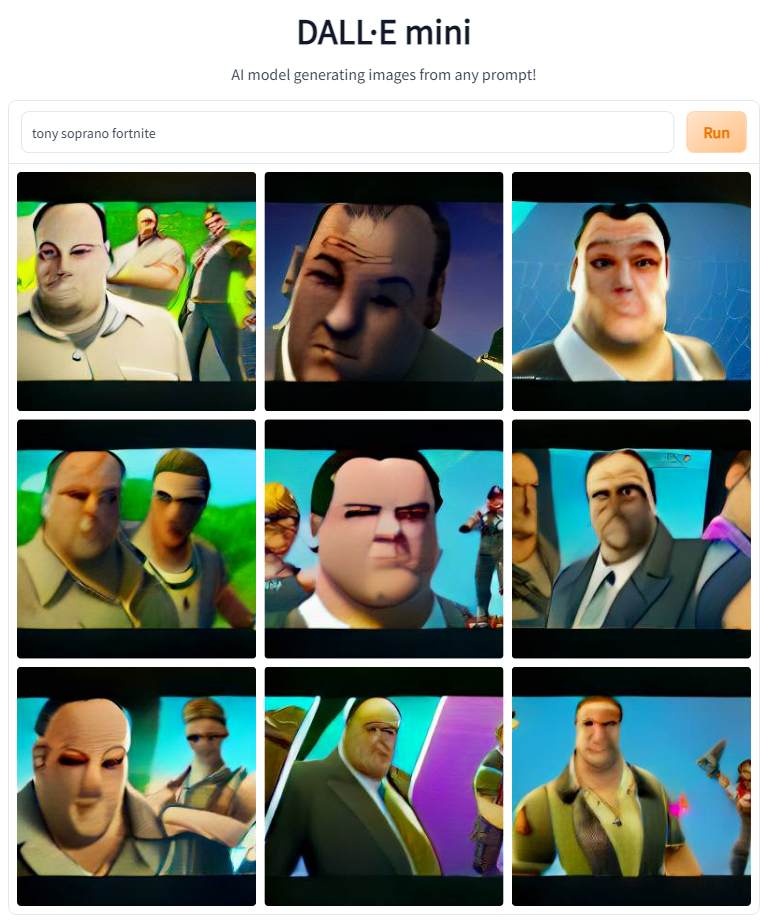
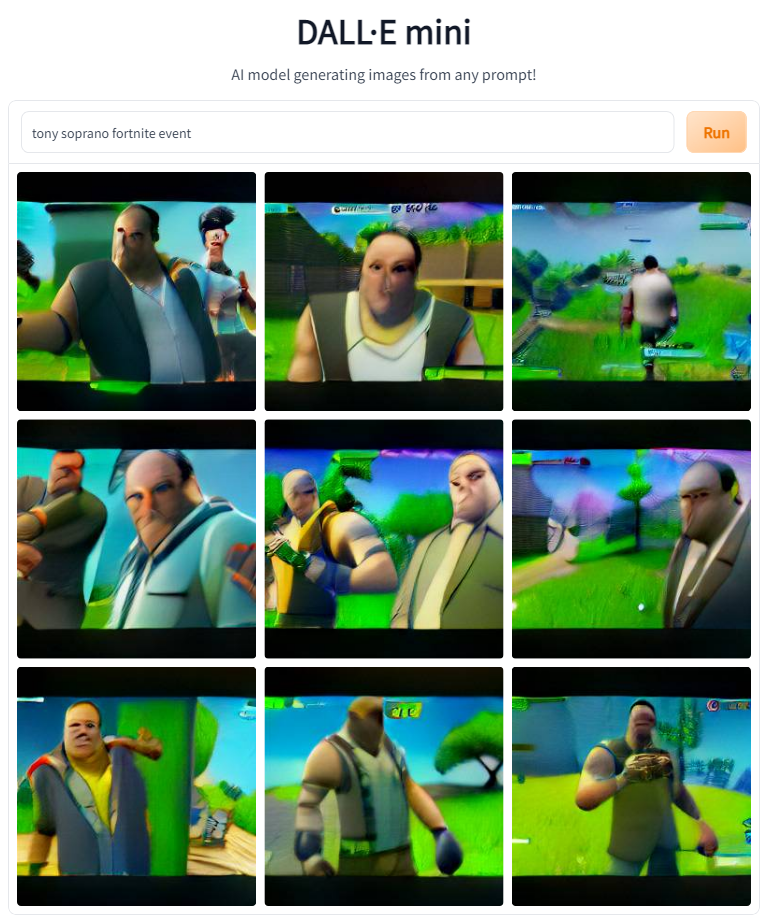
Next up on the list are a number of AAA games. See if you can figure them out before reading the prompts.
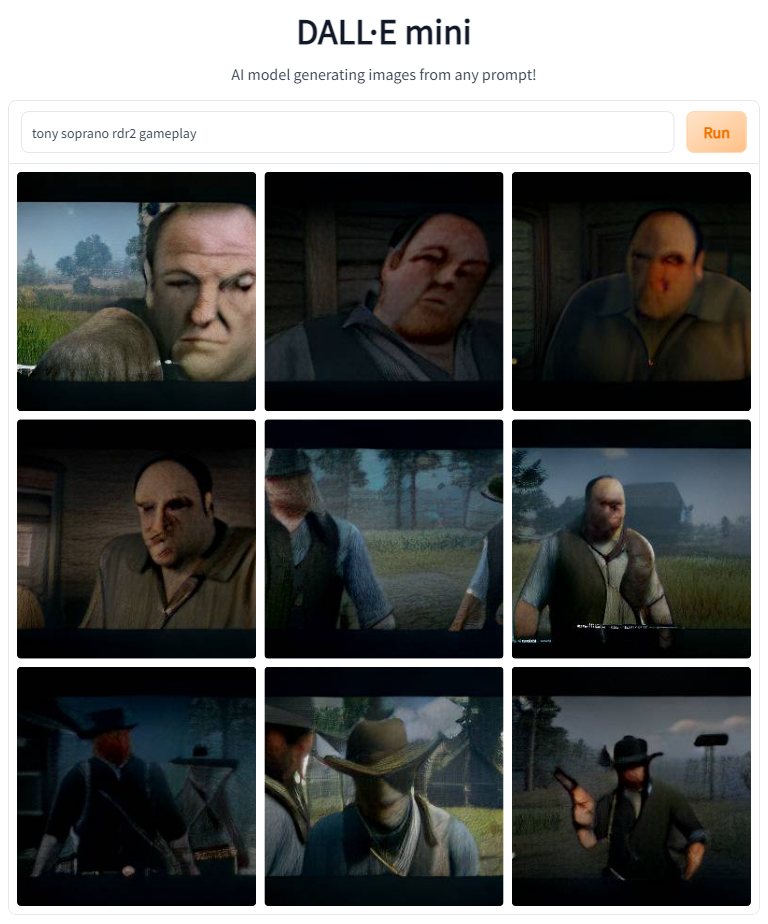
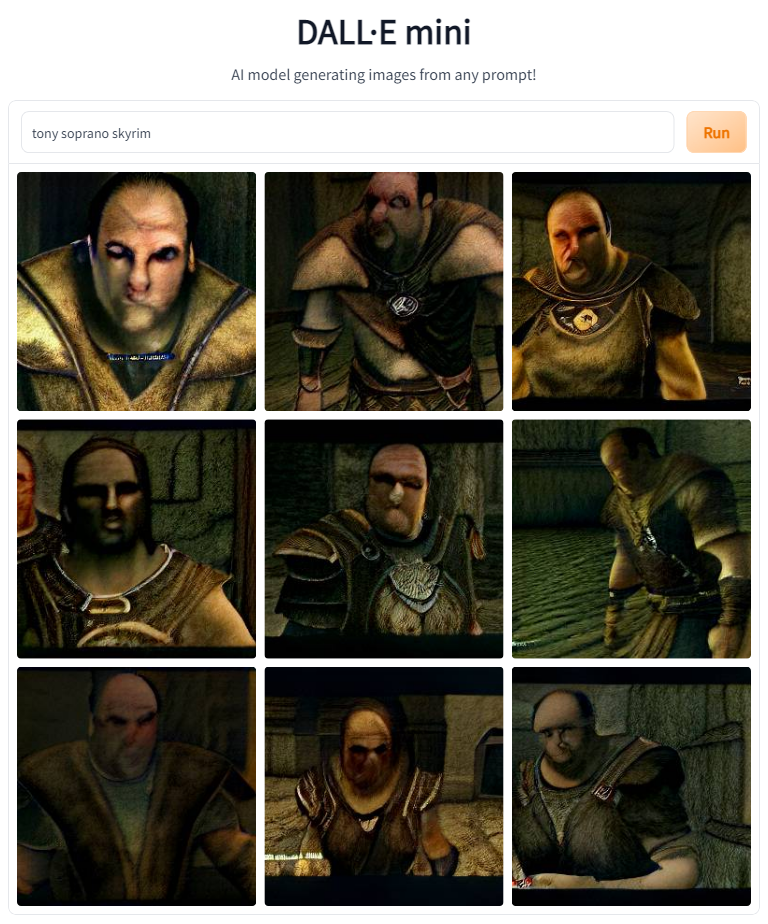
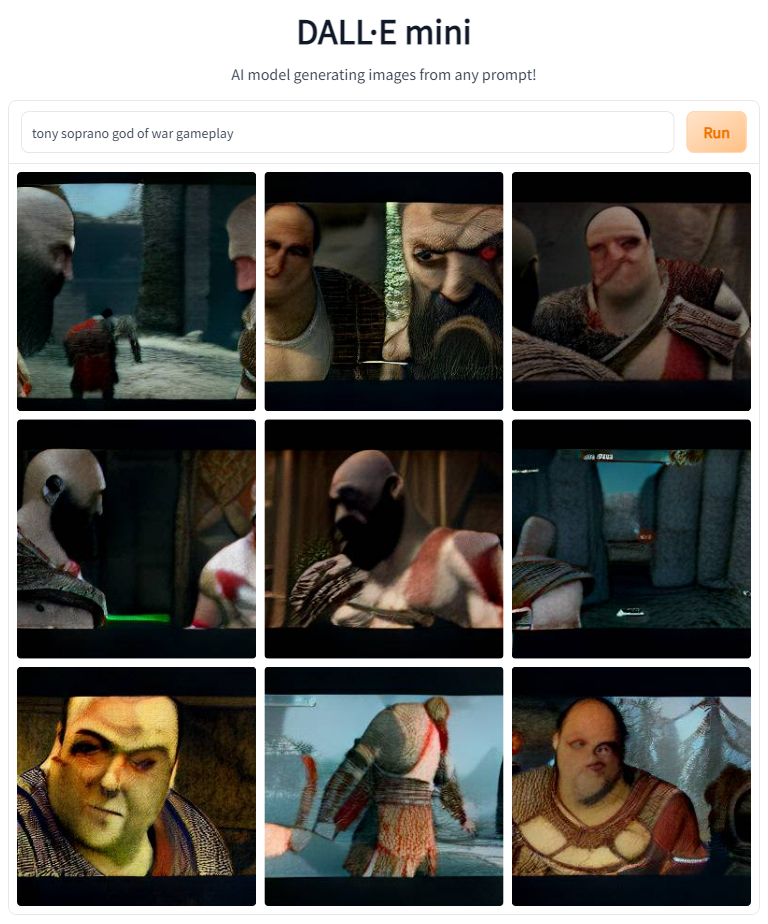
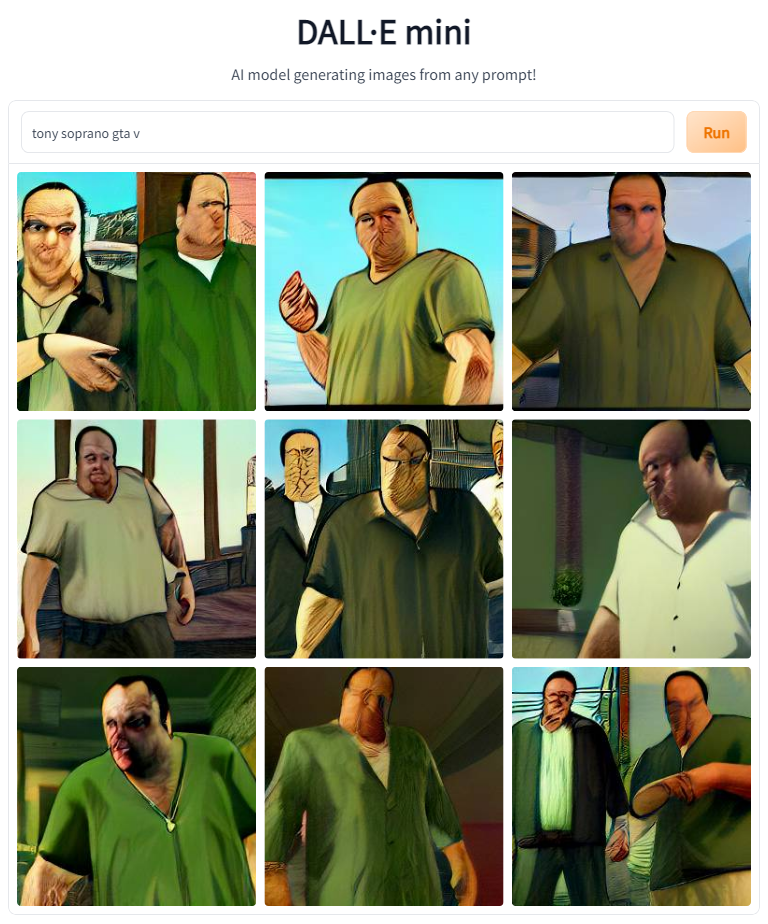
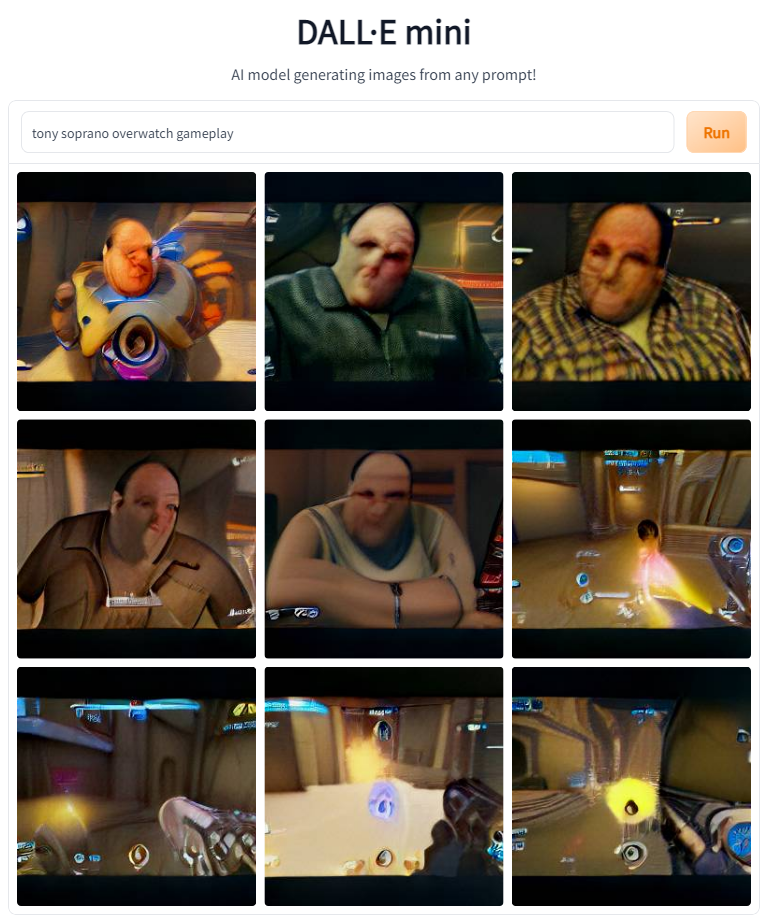
The model did pretty well on all of those. I love the period clothing Tony's wearing in Skyrim and RDR2, and Kratos Tony gave me a laugh.
Bonus Image
Thanks for making it to the end of the post. As a reward, I'll share my favorite image I made during this project.
One of my favorite Christain artists is the 15th century Dutch painter Hieronymus Bosch. Bosch's works often feature nightmarish imagery, particularly in conjunction with themes such as temptation and hell.

Let's see what Bosch's Teletubbies would've looked like.
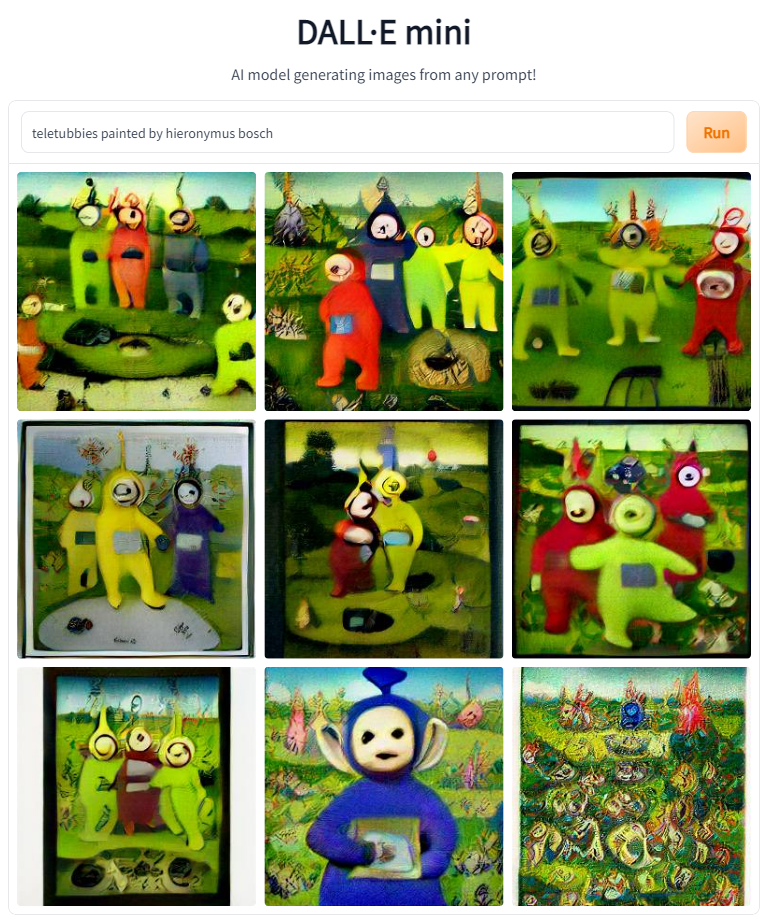
Pretty Amazing.