Similar Verse Finder
I made an AI-powered concordance of the Standard Works
What is it?
In 2022, I did some work as a subcontractor for Scripture Central (formerly Book of Mormon Central). They are an organization that seeks to promote "faith in Jesus Christ by illuminating the Book of Mormon and other restoration scripture, making them more accessible, defensible, and comprehensible to people everywhere."
As part of that mission, they hired me to create some text visualization tools and applying them to the Standard Works of the Church of Jesus Christ of Latter-Day Saints.
One of these tools is a Similar Verse Finder, which lets users input a scripture reference and returns similar verses.
Similarity
How do we determine which verses are similar? Older systems use simple keyword searches. However, this doesn't always work. Consider the following example. Let's say you're reading the Bible and you read in Mark 14:51:
And there followed him a certain young man, having a linen cloth cast about his naked body; and the young men laid hold on him:
And you think, "That story sounds familiar. I think something like that happened in the Old Testament." So you do a keyword search for cloth. Nothing shows up. Undeterred, you do a keyword search for naked. This still doesn't find it.
So you need a solution. Enter the Similar Verse Finder, which uses the embeddings from a language model to calculate a similarity between verses. The language model embeddings are an internal numerical representation of what the sentence means. This representation is robust, so if a verse talks about a few things, they are all captured in the embedding.
In our example, if you were to plug that verse into the Similar Verse Finder, one of the most similar verses is Genesis 39:12
And she caught him by his garment, saying, Lie with me: and he left his garment in her hand, and fled, and got him out.
Even though it doesn't share key words like naked or cloth, both stories are about someone having their clothes ripped off.
How Does it Work?
As mentioned above, this uses embeddings generated by a language model. Just like we store internal representations of knowledge in our brains as thoughts, language models do this with embeddings. Embeddings are high-dimensional vectors, which means we can use linear algebra to calculate the distance between them.
For each verse in the standard works, we embed the verse with a language model. Then we do some math to figure out each verse's 10 nearest neighbors. Then, when the user looks up a verse, we can serve up whichever verses are closest based on these embeddings.
Tutorial
That's all well and good, but how is this actually helpful? I'll walk you through an example. Let's imagine you're reading your favorite psalm, Psalms 23. You get to verse 5 and feel moved by the words. You want to see if there are any similar verses. All you have to do is open up the similar verse finder.
All you have to do is type in the scripture reference (not case sensitive) and hit the submit button.
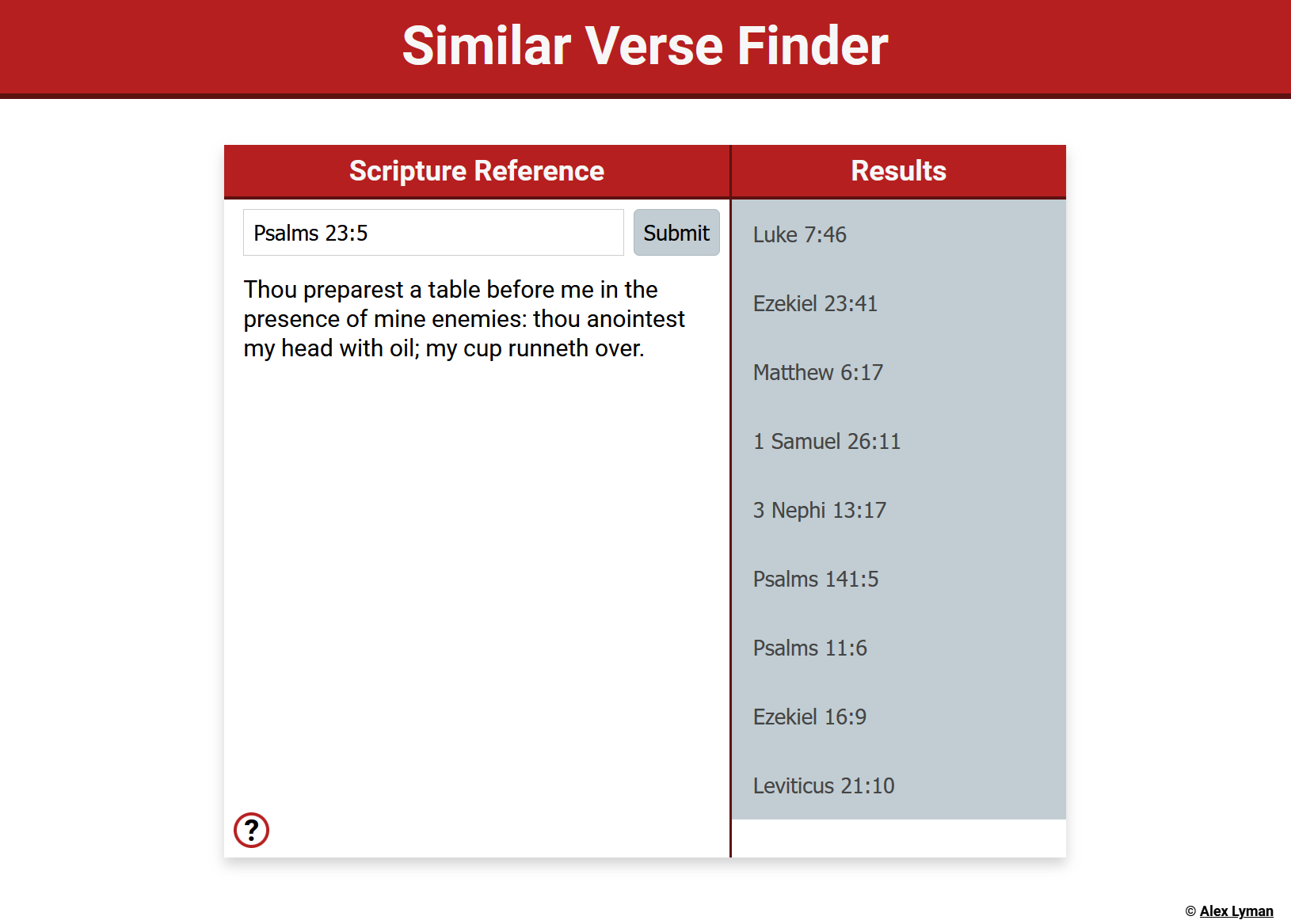
Similar verses are displayed in the results tab on the right.
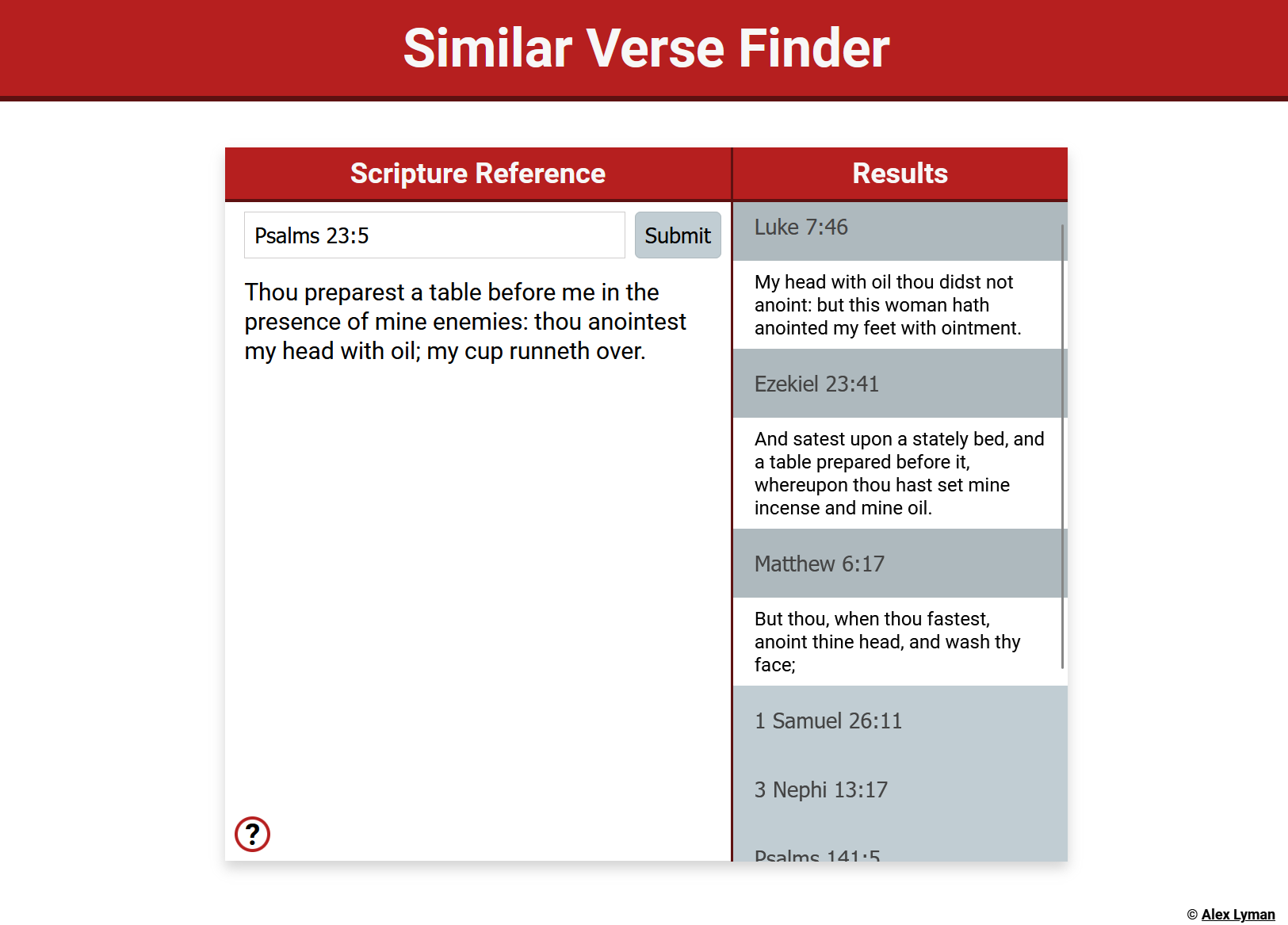
Clicking on the references opens the tabs and shows the full verse texts. We see that in this example we get relevant scriptures about anointing and abundance.
Conclusion
This is a pretty neat tool, and I'm glad I finally wrote it up. But you don't want to read about it, you want to try it out!