BabyLM 2024
What can human language development teach us about language models?
BabyLM Challenge
In 2023, a coalition of researchers held the first annual BabyLM challenge. In it, participants train small language models on a "developmentally plausible corpus" of 10 or 100 million words. 100 million words is roughly the amount a child hears around the age of 12-13 when linguistic development is largely complete. 10 million words is the number children encounter when they start showing linguistic capabilities.
The competition is held as part of the Conference on Computational Natural Language Learning (CoNLL), and submissions are peer-reviewed and published. The aim of the competition is to see what cognitively inspired techniques can teach us about language models and vice versa. Researchers from institutions around the world develop techniques for small-scale language modeling.
My Entry
When thinking about this competition, I thought about how people learn language. One well-known fact is that children who hear more words tend to acquire language faster, and gain better language abilities. There's an analog in machine learning where models trained on more data tend to perform better.
I thought about how when teachers are teaching children to read, they will often ask questions about the test like, "What do you think will happen next?" or "What would have happened if the bear wasn't so nice?" I called up my mom who has a doctorate in educational psychology and asked her about this technique. She told me it was called Reading Prediction Strategies. Reading Prediction Strategies have been shown to help both young readers and second language learners. Could they help language models?
Data Augmentation
How could I train my BabyLM on more data if there's a strict rule on how many words you can train it on? The answer is something called data augmentation.
Imagine you're training a neural net to distinguish between cats and dogs. You gather a bunch of pictures of cats and a bunch of pictures of dogs, and you show them to your model. By coincidence, let's imagine all of the cat pictures you gathered were black cats. In a further coincidence, all of the dog pictures you got happened to be brown dogs. Then, you decide to test your new neural net. You go take a picture of your cat (which happens to be brown) and the neural net says it's a dog!
What happened? Your neural net learned a shortcut for telling cats and dogs apart. Instead of learning things about the shape of the animal, it just guesses based on color. Obviously, this isn't the desired outcome.
Enter data augmentation. In this step, we take all of our pictures of cats and dogs and apply random changes to them. We mirror some images, rotate some by random angles, change some to black and white, color-correct others. In the end, we have 5 times as much training data, and we can use this to train a neural net. With these additional changed images in the training data, our new model learns a more robust and correct notion of cat vs dog.
Method
What does our text data augmentation method look like? We can take sentences from our training data and swap out words for other, similar words. Then, we could make new training examples out of our limited training data. As long as we do a good job of swapping out similar words, our augmented examples will be grammatically correct and make sense.
But how can we swap out words for similar words? We need two things:
- A small part-of-speech dictionary
- A model that knows which words have similar meanings to each other.
We train a Word2Vec model on all 10 million words in our training data. For each word in the training corpus, we get a semantic embedding, or numerical representation of the word's meaning. Because these embeddings are numerical, we can find a word's nearest neighbors, which tend to have similar meanings.
When it comes time to swap words, we select some percent p of the non-function words (nouns, adjectives, etc.) to swap out. Then we replace those words with the most similar word (as defined by our Word2Vec model) that has the same part of speech as the word we're replacing. We replace each occurrence of the word in a training example with the same replacement. This means if we had a story about a bear, and the word bear gets replaced by the word dog, each time the word bear comes up in the story it becomes a dog. This helps ensure semantic coherence throughout the story.
WhatIf is an iterable process, so the data augmentation can be repeated any number n times. Each iteration we use the n-th most similar word from the Word2Vec model. This process can be repeated any number of times to create more and more augmented data of decreasing quality.
Data
We perform all of our experiments on two datasets. Experimenting on multiple datasets lets us know that our results are not an interaction with specific data, but rather the result of our data augmentation. We use 10 million words from the TinyStories Dataset (I've talked about this before), a collection of stories written with a target audience of three-year-olds. We also use the BabyLM Strict-Small dataset, which is the default dataset for the BabyLM challenge. It is made of mostly transcribed speech, much of which is real child-directed speech from the CHILDES corpus. The rest is child-directed written language from children's books.
Evaluation
As part of the BabyLM challenge, models are evaluated on a few Language Model benchmarks. BLIMP and BLIMP-Supplement are grammar benchmarks. GLUE is a question-answering benchmark, and EWoK is a world-knowledge benchmark.
Even though the BabyLM challenge is a competition, our goal isn't necessarily to win. There are many different optimizations that can help with small-scale language modeling. Our main goal is to demonstrate that WhatIf causes improvements over a non-augmented baseline. To this end, we train 20 small GPT-2 models with different data augmentation hyperparameters (we vary n and p).
Finally, we compare our results with a variant of the Contextualizer, the best data augmentation method from last year's BabyLM challenge.
Results
WhatIf causes clear performance gains over a non-augmented baseline. These gains are largely on BLIMP and BLIMP-Supplement, meaning that our method is most helpful for improving grammar ability.
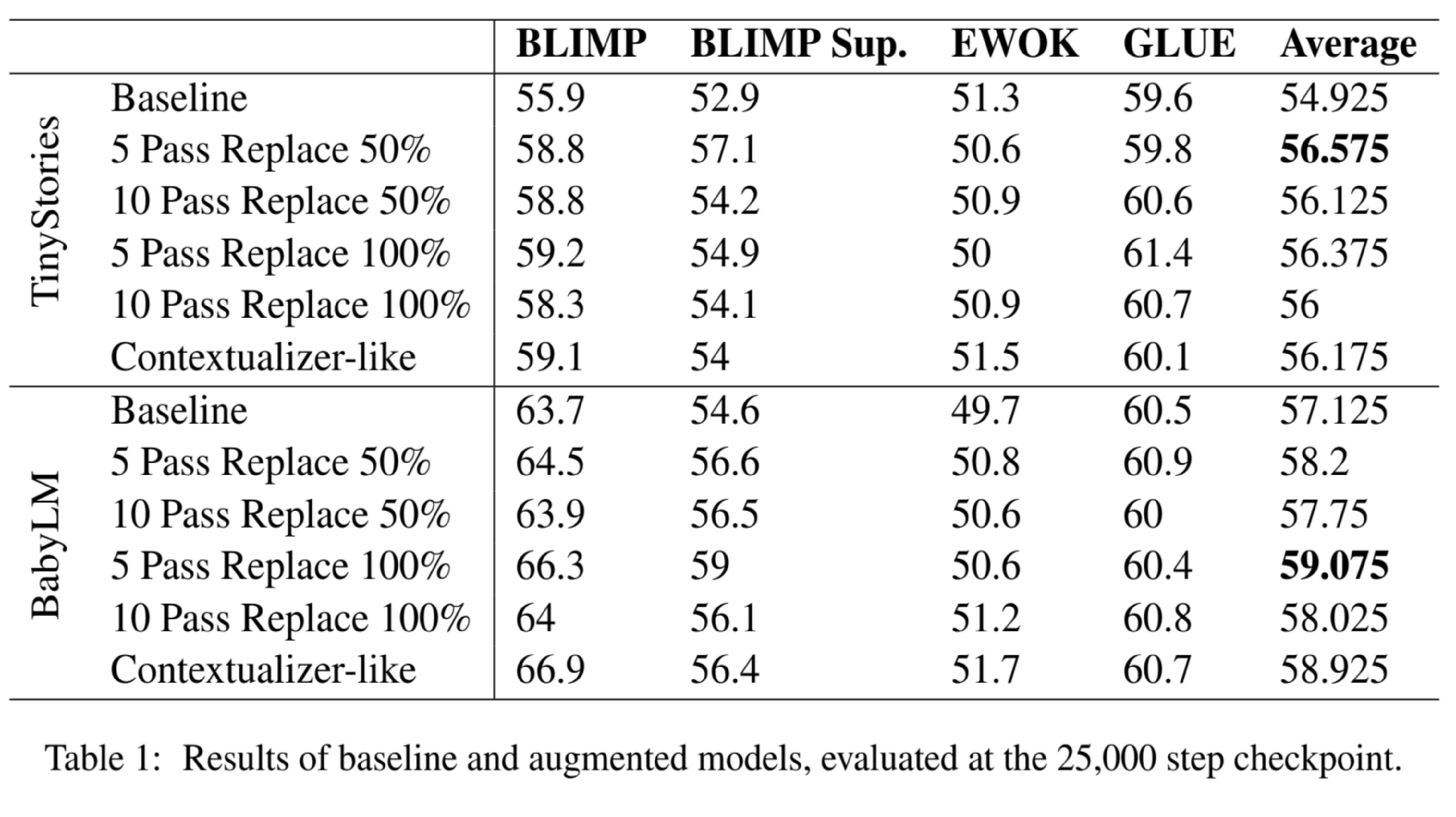
WhatIf performs roughly as well as the Contextualizer, though WhatIf narrowly wins. However, when we try to ensemble both methods, (use both WhatIf and the Contextualizer at the same time) there is no additional performance gain. This suggests that although the methods are very different in implementation, they may be causing improvements via a similar underlying mechanism.
This seems like all good news. There are tradeoffs, however. Qualitative performance suffers with more augmented data. You might expect this. On our 10 Pass Replace 100% condition, for each good training example the model sees 10 augmented (potentially bad) examples. To illustrate this, we show example generations prompted with Once upon a time... for our Baseline (non-augmented) model, our 5 Pass 50% augmented model and our 10 Pass 100% augmented models trained on the TinyStories dataset.
Baseline
Once upon a time, in a big forest, there was a little bird. The little bird lived in a cage. The bird had a mommy bird. The mommy bird could not see the little bird in the cage. The mommy bird was sad...
5 Pass 50% Replaced
Once upon a time, there was a little kitten named Amy. Amy liked to cook with her mom. One day, they decided to cook a big salad for lunch. Amy was very happy. Amy's mom told her, "Amy, can you put the salad in the oven?" Amy opened the oven and put the salad in the oven...
10 Pass 100% Replaced
Once upon a time, there was a child named True. True started to travel with his brother, Bob. They were very stupid at riding games. One day, True returned hurt while they worked. Bob felt confused. He said to True, "I am sorry, let's travel to my parent....
You can see the quality dip slightly on the 5-pass version, and the language is pretty gnarly on the 10-pass one. It is interesting that even this does not really hurt the models' benchmark performance, suggesting some degree of misalignment between benchmark performance and qualitative evaluation.
The Conference
Our work was accepted to the challenge, which meant we got to go to CoNLL in Miami from November 15-16. I went with my co-author, Bryce Hepner.
We shared our work alongside the other participants at a poster session. It was super fun to see other teams' ideas. Many participants and other scientists at the conference talked to us and were really interested in our work. People were constantly asking questions at the poster session, and we met some great people. It was a super rewarding experience.

Results-wise, we were in the middle of the pack for the competition. Since we were more focused on showing that our technique worked than on winning, I was very pleased with these results. Several of the other models we outperformed had more parameters than ours, so adjusted for size, we did quite well.
It was also cool to go to Miami for the first time. The city was interesting and vibrant, and we got to try some great local food.




Conclusion
I enjoyed coming up with this data augmentation technique, and it was great to get to go share my work in Miami. I'm starting to feel like a real academic. If you're looking for a more in-depth, technical explanation, you can read the full text of the paper here.