Transcribing a Spoken Corpus
I set up a custom AI pipeline to transcribe over 1000 oral history interviews
Joey Stanley and the Kohler Tapes
In 2024 I met Joey Stanley, a linguistics professor at BYU. A few years ago, Joey (a phonetician), came into possession of several hundred audio tapes recorded in Heber, UT. Norm Kohler, a Social Studies teacher at Heber Middle School, assigned each of his students to record an interview with one of their grandparents. He had students do this from the '80s until his retirement in the 2000s. Norm's dream was to create a history of the Heber/Midway area, but was unable to bring his plans to fruition before passing away.
After Norm's passing, his family put an ad in the paper, and returned hundreds of tapes to the former students who had recorded them, but most of the tapes remained unclaimed. These were donated to the Heber historical society, where they sat until Joey found out about them. He was able to digitize all of the tapes with assistance from the BYU Office of Digital Humanities.

If you're interested in hearing more about the tapes, Joey has written several blog posts on the topic.
When Joey got to know me and had an idea of my skillset, he mentioned this project to me. It sounded like a meaningful project, so I offered to help him transcribe the tapes using modern AI tools.
The Tapes
As part of getting familiar with the data, I listened to several of the tapes myself, which was an interesting experience. The interviews evolved with time. Mr. Kohler (as he was known to his students) developed the assignment as the years went on, so the early interviews are highly unstructured. Later, they had specific questions to ask.
The grandparents in the interviews were born between the late 1800s and mid 1900s. They had some pretty remarkable stories and lived through world wars, the great depression, and profound technological change. Many of the interviewees were the first people in their family to ride in an airplane or own a TV. Frankly, the tapes are a treasure trove for historians, linguists, and descendents of people from Heber.
Many of them lived interesting rural lives which were very different from mine. Their stories remind me of my own grandparents' stories. (My maternal grandparents were from Lovell, Wyoming, and my paternal grandparents from Delta, Utah.) It's very touching to hear these people talk to their grandkids, expressing their hopes, dreams, and memories. Many of the interviews end with heartfelt expressions of how much they love and appreciate their grandchild who's performing the interview.
The audio I needed to transcribe started its life on cassette tapes which were 20-40ish years old. Since middle-schoolers performed the interviews on household equipment, they didn't always record the best audio. In spite of that, most of the audio was good enough for us to proceed with transcription.
Here are a couple of short snippets from different interviews to give you a feel for what the tapes are like:
Transcription
Transcribing audio seems like a pretty simple task on the surface, but is more work than it seems. Paying someone to transcribe audio can cost a lot. At his first estimate, Joey figured it would cost tens to hundreds of thousands of dollars to transcribe the tapes.
But that doesn't seem necessary. If Siri can understand you, it seems like you should be able to get a computer go transcribe tapes like this, right?
I thought so, and I spun up Whisper Large v3, a transcription model from OpenAI. At the time, it was the best publicly available model for audio transcription. Even now, a few years later, it's still one of the best transcription models out there.
The Whisper transcriptions were very high quality, all things considered. However, they weren't exactly what we needed. Since Joey's a phonetician, he needed really accurate transcripts. Whisper creates transcriptions that are edited for clarity, while still being close to the original audio.
Maybe you've encountered this while watching a video with subtitles. The dialogue on screen is fast and complicated, and the subtitles show a shortened version that people would be able to read.
We wanted transcriptions that would capture all the messiness of real speech. If someone said 'um' or 'uh', we wanted that information. After a search, I found CrisperWhisper, a version of Whisper that was fine-tuned to do verbatim speech transcription.
The transcription models weren't perfect. These models have a WER (Word Error Rate) of around 7. That means that 93% of the words are correct, with 7 mistranscriptions, insertions, or deletions per hundred. While that is an A, it's not great. These interviews can have a few thousand words, which means we would expect a couple hundred errors in each transcription. That's not ideal.
Actually performing the transcription was a hassle. We had over 1,200 audio files in .wav format (about 80 GB of audio). Running a model like Whisper on a long audio file is also a hassle. I had to spin up a couple of GPU nodes on the BYU supercomputer to run the transcriptions with both transcription models.
These transcription models can't just transcribe 25-minute long interviews. When you run them, they actually cut up the interview into 30 second chunks and stitch them back together. CrisperWhisper had a bug with its chunking algorithm, so I had to manually chunk and stitch my audio. About 5% of the time, some bug made CrisperWhisper fail without explanation. This bug was documented (several other people encountered the same issue), and I found a solution.
I was able to find a workaround though. I decided to transcribe everything twice, using the CrisperWhisper transcriptions as a 'gold standard', with Whisper as a backup where CrisperWhisper failed.
This let us leverage the fact that we transcribed the interview twice with two different models. If we assume that the two models' errors are independent, (probably not a correct assumption, but we're gonna go with it) we can reduce the error rate from around 7% to around half a percent. To be able to do that, though, we needed to have a surefire way of picking the correct transcription where the two models diverged.
LLMs for Combination
Nowadays we have AI to help us with tasks like this. I spent a long time working to create a prompt to get a Large Language Model to do this for us. Creating the prompt took hours of iterating, explaining the task, adding examples, adding instructions, etc. I wanted the AI to be able to leverage its knowledge to standardize spellings, correct mistranscriptions, and stick the two transcripts together. Joey had previously had an RA listen to the beginning of each tape and try and figure out the name(s) of the person or people being interviewed, so we gave that human-generated data to the AI as well. The process was iterative. I wrote a prompt, tested it on a few interviews, and tweaked the prompt until I was hitting peak performance.
Here's the prompt in all its glory:
You are an expert evaluator.
I have a collection of interviews done as part of a middle-school assignment in the city of Heber, Utah from the 1980s to 2000s.
Each interview is a middle-schooler interviewing one or more grandparents about their life.
The audio is from a digitized cassette tape.
A person has gone through and listened to the beginning of each tape to try and find the names of interviewers and interviewees.
We are planning on performing linguistic analysis on the tapes, and for this we need very high quality transcriptions.
These transcriptions need to be as accurate as possible, including false starts and disfluencies like [UM] and [UH].
Each of the interviews has been transcribed with two different text-to-speech models.
Model A is very accurate with disfluencies and timestamps.
However, it was trained with hallucination mitigation, so occasionally it doesn't transcribe speech even where speech occurs.
This means that sometimes it will only pick up one voice on the transcript when there are multiple voices.
Model B is the backup transcription. It does longform transcription pretty well, though it omits disfluencies and false starts.
It is also a little loose with the timestamps, and very occasionally hallucinates audio that is not on the tape.
The transcription models do not have a lot of world knowledge.
For example, in one transcription, the grandpa says he was born in 'mid-Norway, youth town.'
The other transcription says, "Midway, Houston".
Neither of these are real places.
However, the town of 'Midway, Utah' is 3 miles away from Heber.
You should use your world knowledge, combined with the audio and the transcriptions to guess what is likely correct.
To help you, here is a list of cities and towns within 20 miles of Heber:
Midway, Francis, Park City, Kamas, Snyderville, Oakley, Highland, Cedar Hills, Summit Park, Alpine, Lindon, Pleasant Grove, Orem, Granite, American Fork, Cottonwood Heights, Little Cottonwood Creek Valley, Provo, Mount Olympus, Sandy Hills, Draper
Similarly, most (but not all) respondents have ties to the Church of Jesus Christ of Latter-Day saints. Use your knowledge of church history to correct likely mistranscriptions.
For example, in one transcribed interview, the interviewee mentions that she is a descendent of "Brigamion". This is a mistranscription of Brigham Young.
You should also use world knowledge to correct spellings and fix capitalization.
If you are **confident** a word is misspelled or was misheard by the transcription model, correct its spelling.
As mentioned, we have gold-standard spellings for some names.
Take into account the following human-generated data while correcting spellings:
{human_data}
I have given you transcriptions from Model A and Model B.
For greater context, I've also included the plain-text transcript of the whole interview.
Your job is to combine both transcriptions into one very accurate transcription, primarily based on the Model A transcript.
Accuracy is more important than fluency, so make sure to include the false starts and disfluencies from Model A.
Model A is more accurate, so in general you should favor the Model A transcription, making sure to add words from the Model B transcription.
Use common sense while transcribing.
You should also use the gold-standard human data and your world knowledge to correct spellings and likely place names.
Also, turn all transcribed numbers into words. For example, 96 should be ninety-six.
You should use common sense to determine whether words that occur in only one tape are hallucinations.
If they seem to fit in the context of the interview, keep them. Generally, you should keep words if unsure.
If two transcripts have different (but similar sounding) words in the same place, choose the one that makes more sense.
Usually, hallucinations take the form of a word or phrase repeated many times where repeating several times doesn't make sense in context.
Your job is NOT to copy edit, but rather to make the combined transcription that is most faithful to the reference transcriptions, favoring the Model A transcript.
That means if you see a disfluency like 'and [UM] then my on my father's side'
you should NOT edit that for clarity, but keep the whole '[UM] then my on my' phrase.
NEVER omit [UM] or [UH] if either occurs in either transcript.
While you are supposed to correct obvious misspellings and erroneous place names/obvious mis-transcribed words, do not remove disfluencies or false starts.
For example, if the Model A transcript reads,"My grand my grandkids", grand is a false start and should not be omitted, even if it does not occur in the Model B transcript.
Make an effort to include as many words from both transcripts as possible. For example, if Model A says "And [UH] then [UH] I was Miss Wasatch" and Model B says "And then in 1928, I was Miss Wasatch"
You should in that case say "And [UH] then [UH] in nineteen twenty eight I was Miss Wasatch".
Do not forget, your job is to make the transcript as accurate as possible to the source material, not to edit for fluency or clarity.
Sometimes, people talk over one another. Your job is not to make these into two clean, sequential utterences, but rather to report the words in the order they occur in the transcription.
This is unlikely, but it is possible that there has been an error with the transcriptions (maybe they really don't match or they don't appear to have an interview on them. These are digitized cassette tapes, so there are lots of potential issues) If you are confident the transcripts do not contain an interview, or if the transcripts are so disparate you absolutely cannot merge them, do not output a transcript. Only output the phrase: FLAG FOR REVIEW
Your output should ONLY include the corrected transcript with one sentence on each line. For example, given the following transcript chunks:
Model A:
My name is Mindy Smith. It's May 3rd, 1995 and it is 625. Okay. Name some of the oldest people you can remember and can you describe them? Well, let's see. I remember my grandfather. He was 96 when he died. He was a jolly fellow.
Model B:
Okay. Name some of the oldest people you can remember and can you describe I remember my grandfather. He was 96 when he died. He was a jolly fellow.
You would output the following:
My name is Mindy Smith.
It's May third, nineteen ninety-five and it's six twenty-five.
Okay.
Name some of the oldest people you can remember, and can you describe them?
Well, let's see.
I remember my grandfather. He was ninety-six when he died. He was a jolly fellow.
Here are the full, unedited transcripts
Model A:
{model_a_transcript}
Model B:
{model_b_transcript}
Output only the FULL combined and corrected transcript. Don't explain your rationale or anything else. Do not add comments. Do NOT truncate your output.
And that's without the human data or transcripts piped in! If there's one thing you should take away from this, it's that if you want an AI system to do a good job on a complicated task, you need to be very specific and work on your prompt a lot.
I also needed to select the right model for the job. My lab has really high-tier API access to OpenAI's models, so I was going to use them as a provider. OpenAI offers a lot of models. Some are smarter and more expensive, and I wanted the most bang for my buck. Once again, I needed to test things out. This project took a while, and at the beginning, I was using GPT-4.1 (their best non-reasoning model), but as time went on more models came out. GPT-5.2 (the current newest model) has a tuneable 'reasoning effort' hyperaparameter, so I tried using it with various levels of reasoning. They all performed about as well as each other (and better than 4.1), so I went with GPT 5.2 with no additional reasoning.
LLMs for Filtering
Of course, you can imagine that not every side of every tape contained an interview. They were, after all, recorded by eighth-graders on tapes they had lying around the house. Many of the tapes had an interview on one side, and random audio on the other. A few tapes had recorded the interview over something else, and as soon as the interview ended a mixtape staerted to play. There were even a couple of tapes with no interview on either side!
Once again, the LLMs came in clutch here. We could pass the transcript to the LLM and have it figure out if the tape had an interview at all, and then if the tape had additional copyrighted audio on it. Because we are intending to distribute this as a text and audio corpus, we had to make sure we weren't distributing radio music or anything else that might get us in trouble. We had a smaller model (GPT 5.2 mini) identify tapes that had issues. This was a simpler task than combining long transcripts, so we could use a smaller, cheaper model.
Then, I manually reviewed each tape that was flagged to ensure the LLM didn't make a mistake. Some of the things on the tapes were pretty funny. We ended up getting rid of 141 tapes that either did not contain an interview, or were too badly degraded to be intelligible.
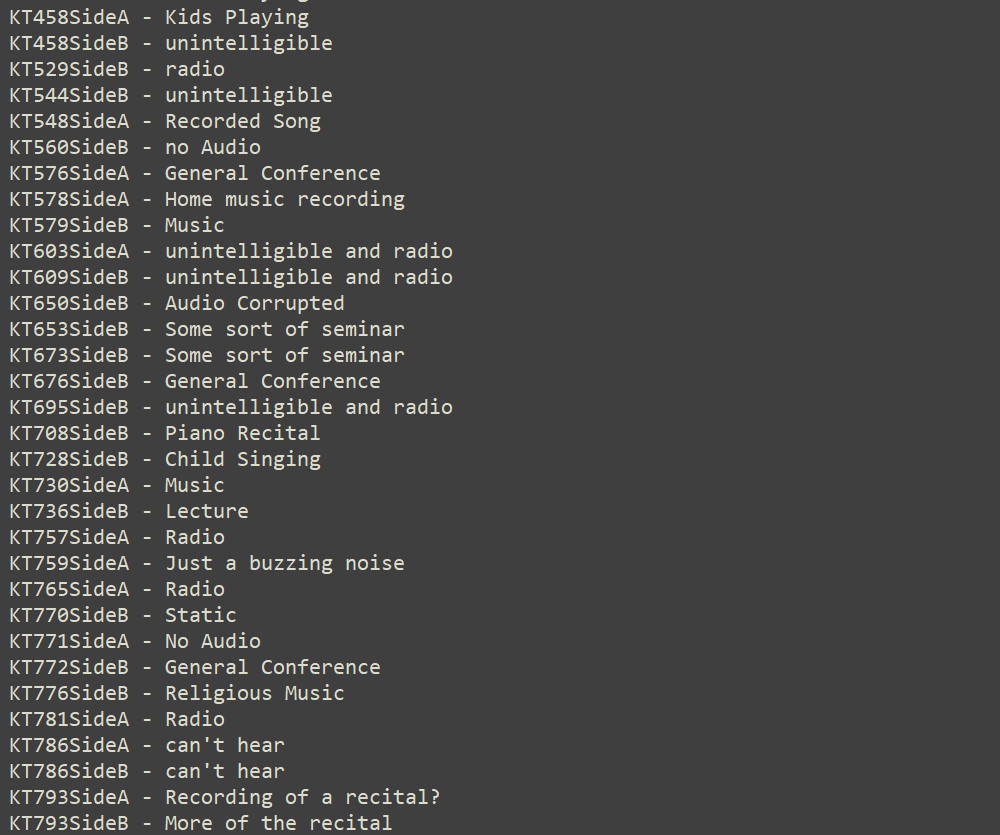
Here are a couple of non-interview tapes. The first is a kid reading the Gettysburg Address in a silly voice, and the second is an example of a tape with audio too poor to transcribe.
We also had to trim 79 tapes that contained an interview followed by copyrighted audio (usually either radio music or General Conference). I also did each of these individually.
This is an important point. I individually inspected each of the 200+ tapes we either edited or discarded to make sure the LLM wasn't misidentifying things. As you use AI for tasks, you should be sure to incorporate human oversight into your process.
The Transcripts
I'm sure you're wondering how the transcripts turned out. Here's an example of what our pipeline puts out:

Overall, this is great. The model gets a little confused with the crosstalk and misplaces the phrase, 'you know'. However, it does a great job at correctly transcribing nonstandard English ('run and got it all over 'em') and transcribing the disfluencies and false starts. This is way better than a normal model will do out of the box.
As I mentioned earlier, Joey's a phonetician, and having well-aligned transcripts was really important to him for his phonetic research. In addition to plain text versions of the transcripts, I created TextGrids (special linguistic-focused files) for each transcript. Here's a TextGrid open in Praat (linguistic software), to show how well the transcripts match up with the audio. They're basically perfect.
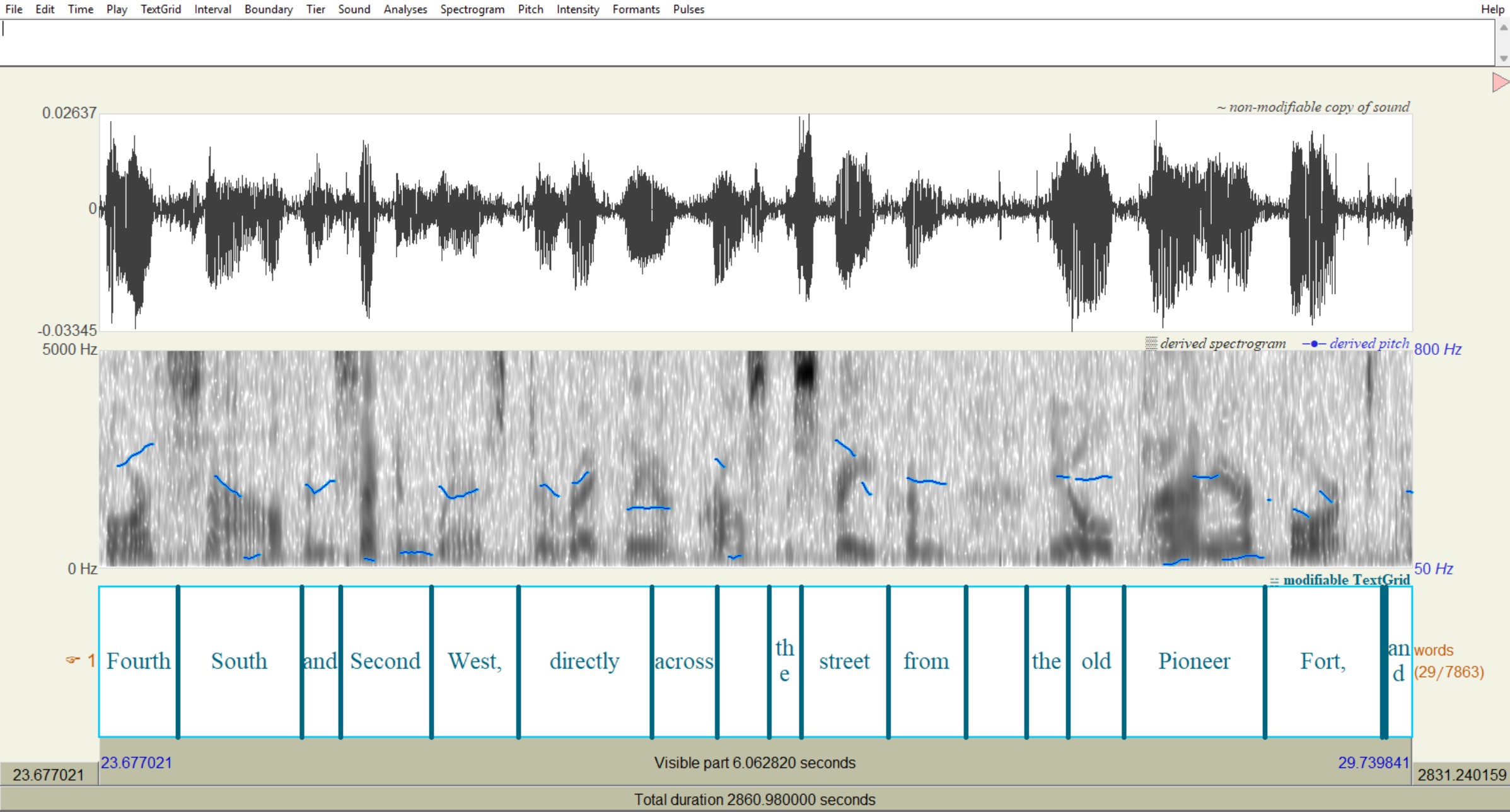
What's Next?
My involvement with this project isn't over yet. I'm helping prepare the audio and text files to distribute as a corpus for other researchers to use. We're also planning to get the tapes written up nicely as a 'thank you' for the Heber Historical Society. It would be great if the interviewees' descendents had access to these interviews, so we're hoping to circulate news of the tapes once published.
And that's just the beginning. Joey's going to be doing a ton of phonetics research, and with AI we can extract information from the corpus in an unprecedented way. Models can infer interviewees' politicization from interviews (Mr. Kohler had the students ask their grandparents who their favorite presidents were.) We can automatically extract names from interviews, and create a social network (who knew who, who was related to who) of the interviews. After extracting locations in and around Heber, we can make a custom map of the town with audio from the tapes corresponding to different places. There are so many exciting possibilities!
Presenting the Tapes
Joey and I spent Saturday, Feb. 21 at Weber State University in Ogden, UT for the DHU (Digital Humanities Utah) 10th annual conference, where we presented the initial version of the tapes and our transcription pipeline.
I'd never been to Weber State before and I had a few thoughts:
- It was really far! Since it's still in Utah, I didn't think it would be quite such a commute. It took over 2 hours on the train and another 20 minutes on the bus each way. It took so long that I was late for the lunch and there were only vegetarian lunches left. My $30 conference registration got me a sad cauliflower wrap.
- The Weber State campus is like a dream version of the BYU campus. The buildings are similar, and they also have a statue of a weird humanoid cat mascot (pictured below). However, it's not laid out like BYU, so it felt a little 'wrong' (especially since nobody was on campus that day since it was Saturday, which was a little eerie).
- I don't really care about Digital Humanities that much. There were multiple talks by librarians, and it was just not my cup of tea.
- People were very interested in our methodology and contribution. More questions were asked after our talk than any other talk I attended, so at least we were interesting.




The tapes haven't been published yet. Eventually, we'll write up a paper and publish the whole corpus for public use. I'll write another post when the time comes.