Exploring How LLMs Microtarget Persuasive Messages
In a follow-up paper to previous work on microtargeting, we examine in-depth how LLMs target persuasive messages, and what effect that has on persuasion.
Political Microtargeting with LLMs
Last year, my team and I published a paper on political microtargeting with Large Language models. (blog post) (paper) Not to toot my own horn, but it was a good paper. It won a best conference paper award at APSA, the main conference for the American Political Science Association.
The motivation for the paper is the fact that big companies have our data. With LLM technology, it's possible that they could use your information to tailor messages specifically to you, and make them as persuasive as possible. To test this, we paid a few thousand people to either have a conversation with an AI agent, or to read a message generated by an AI agent. Sometimes, the AI had access to the person's demographic information, and was instructed to microtarget the message to the respondent. Other times, it just wrote a message with no extra information. The AI was trying to convince the person to change their mind on a randomly assigned topic (Immigration or K12 teachers bringing their personal views into the classroom).
We found that the AI was persuasive, and succeeded in getting people to change their opinions on these political topics. However, there was no statistically significant evidence to suggest that the LLM was more persuasive when it had access to the person's demographics. There are a lot of potential reasons for this. Here are a few we thought of:
- Maybe the LLM was bad at microtargeting.
- Maybe the LLM microtargeting inconsistently.
- Maybe the LLM wasn't microtargeting at all.
We didn't know which was the reason. And we weren't the only ones. As we presented this work, we got the same question over and over again: What exactly was the AI doing when asked to microtarget?
Chinese Political Science Review
Last year, a group of Chinese scholars reached out to our lab. They were interested in increasing collaboration with Western scientists working in the area of AI and social science. Because of previous work our lab had done, we got an invite. It was a pretty good deal. They would pay all expenses to send one of our lab members to a conference in China, provided we prepare a publication for the journal Chinese Political Science Review.
Well, it seemed like a good opportunity, and we had kind of wanted to write this follow-up paper, so we decided to send my friend Ethan Busby to China. He had a great time at the conference, and we had a paper to write.

As a note, Chinese Political Science Review is a journal about Political Science in general that happens to be published in China. It is not specifically about Chinese Political Science.
The Paper
In our original study, we had several conditions, some where the participant had an active conversation with the AI, and some where the AI wrote a single message for the participant to read.
For this paper, we decided only to examine the single-message conditions. We made this decision because in dynamic conversational conditions, what the respondent says helps to steer the conversation. Differences between these conversations may be a result of what the respondent said, and not some internal process of the LLM. We wanted to be sure that the variation we saw was due to differences in LLM behavior.
That left us with just over 1200 messages across topic (Immigration or K-12 classrooms) and direction (More or Less Conservative). Not only did we have the messages, we also had downstream persuasion outcomes from over 1000 people. This meant we could see not only how the LLM targeted its messages, but also what effect that had on real persuasive outcomes.

When we sat down to think through this paper for the first time, we came away with a few questions:
- Is the model even microtargeting?
- What is the difference between the static and microtargeted messages?
- When we ask the model to microtarget, does it target systematically based on demographics?
Is Microtargeting Happening?
The first question we wanted to answer (which we only touched on in our original study) was, "Is the model even microtargeting?" To answer this question, we use Qwen-3-Embedding-4B to embed each message (turn it into a vector that represents the meaning of the message). Then, we project the messages into two dimensions using UMAP.
What that does for us is give us a 2-d graph where messages that talk about similar things are close to one another in the graph.
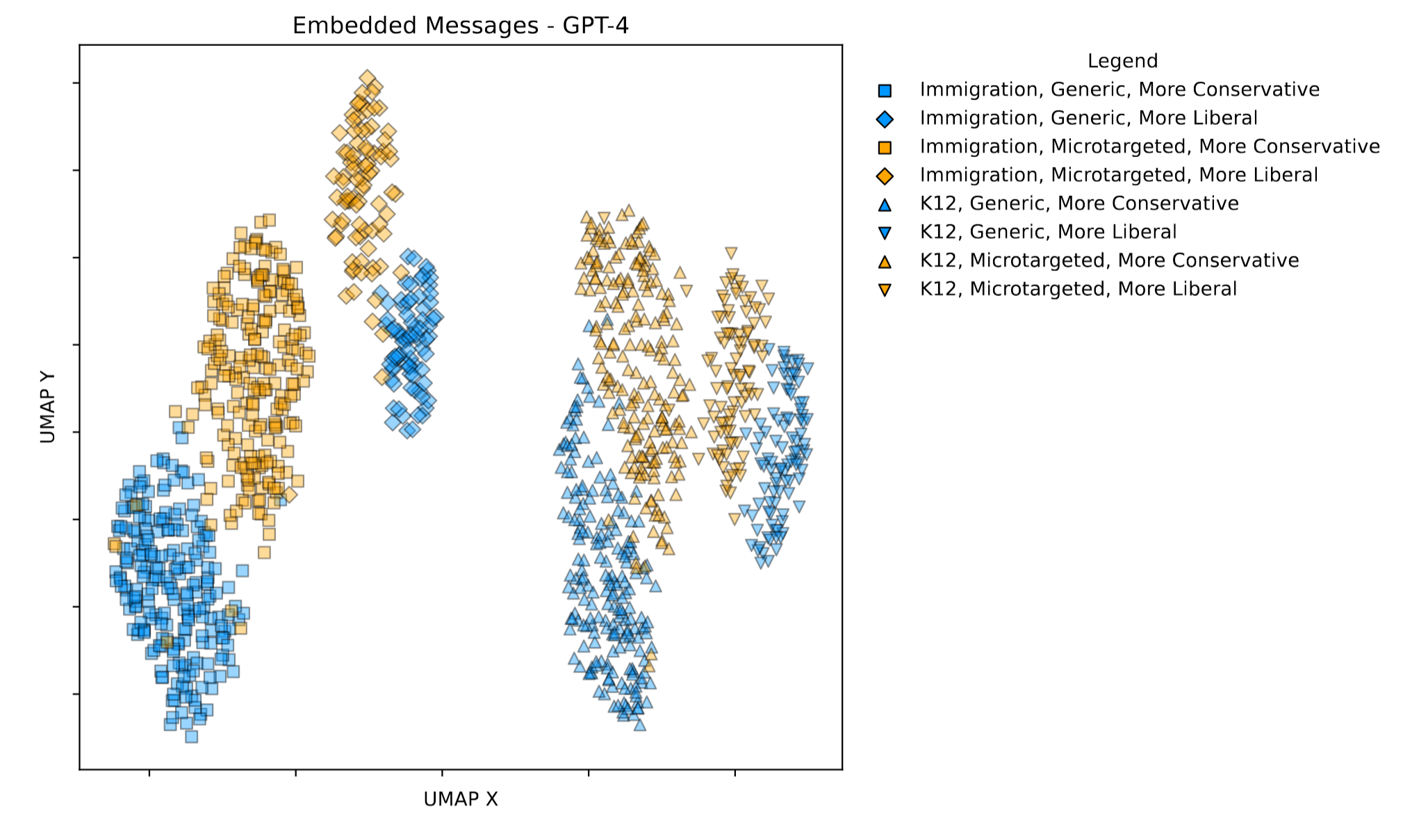
This graph is really information dense, so let me break it down for you.
In the study, each person was persuaded away from their original opinion. That means if they initially had a more liberal response, they would be persuaded in a more conservative direction, or vice versa. Each person was also either Microtargeted (the LLM had access to the person's demographics) or Static (the LLM didn't know anything about the respondent.) Finally, each person was randomly assigned to one topic, either Immigration (the government should do more to prevent illegal immigration) or K12 Education (the government should do more to prevent teachers from bringing their personal opinions into the classroom.)
We had to convey all of that information in the graph. If the person talked about Immigration, the point is a square. If they discussed K12 Education, the point is a triangle. If the person was in a microtargeted condition, the point is blue. If it was static, the point is yellow. If the person was being persuaded in a more conservative direction, the shape is 'sitting on the bottom'. Otherwise, it is rotated.
So what does the graph tell us? Looking at the graph, we see clear separation between topics, conditions, and directions. This makes us pretty confident that the model is generating different messages based on topic, and that the microtargeted messages and the static messages are distinct. Because we see clear separation based on direction, we can also infer that the model isn't just writing the same message and adding 'not' based on the direction of argument. Instead, it appears to be writing distinct messages with different arguments in both directions.
This embedding chart gives us a good foundation for saying that the model is customizing the messages. However, it doesn't tell us anything about the particulars. To find out, we performed extensive analysis on all of the messages.
Difference Between Static and Microtargeted Messages
In order to differentiate between our messages, we needed to know as much about the messages as possible. We evaluated every single message on several axes:
-
Persuasive Strategies
LLMs, or any persuaders, have a slew of persuasive and rhetorical strategies at their disposal. While we can't provide a complete breakdown of these, we quantify some of the common persuasive strategies that are used.
-
Emotional Tone
Emotional tone has been shown to have an effect on persuasiveness. The LLM might be trying to evoke different emotions, either with tone or content.
-
Informational Content and Density
There's a lot of work that suggests that both the type and quantity of information are important factors in persuasion. We look at information density and content across the messages.
-
Values-Based Appeals
Persuaders often tailor arguments to their respondents. One common tactic is appealing to shared principles (or perceived shared principles.)
-
Obvious Targeting/Pandering
Even though the LLM was told not to do any explicit microtargeting in the original study, that doesn't mean none took place. We examine the LLM messages and demographics for obvious targeting or pandering based on demographics and ideology.
-
Structural Features of the Message
It's also possible that messages differ on structural factors like length or text complexity, which we measure.
These metrics could be used both to determine how/whether static and microtargeted messages differed from one another, and whether the model was targeting systematically based on demographics.
Now, evaluating thousands of messages for topics, rhetorical strategies, etc. is a lot of work. We (I) had an LLM annotate all of the messages for all of these topics and strategies. This involved lots of different prompts, and several passes through the messages.
So what did we find?
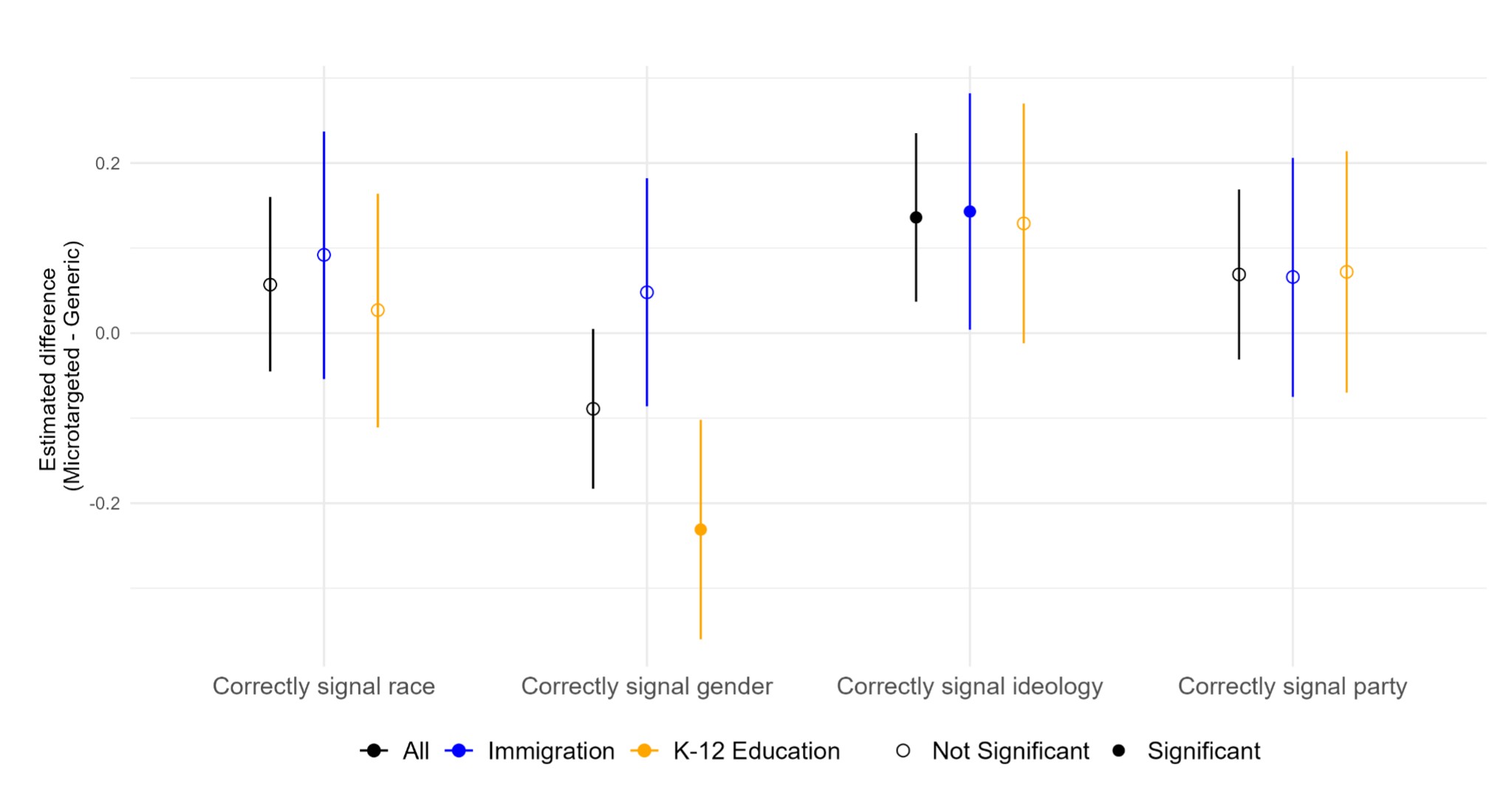
We made a bunch of graphs about this, and the graphs aren't super intuitive, so here's an explanation. What we were searching for is a difference between static (non-microtargeted) and microtargeted messages. These graphs show the difference between microtargeted and static messages, broken up by topic. Higher values represent larger differences.
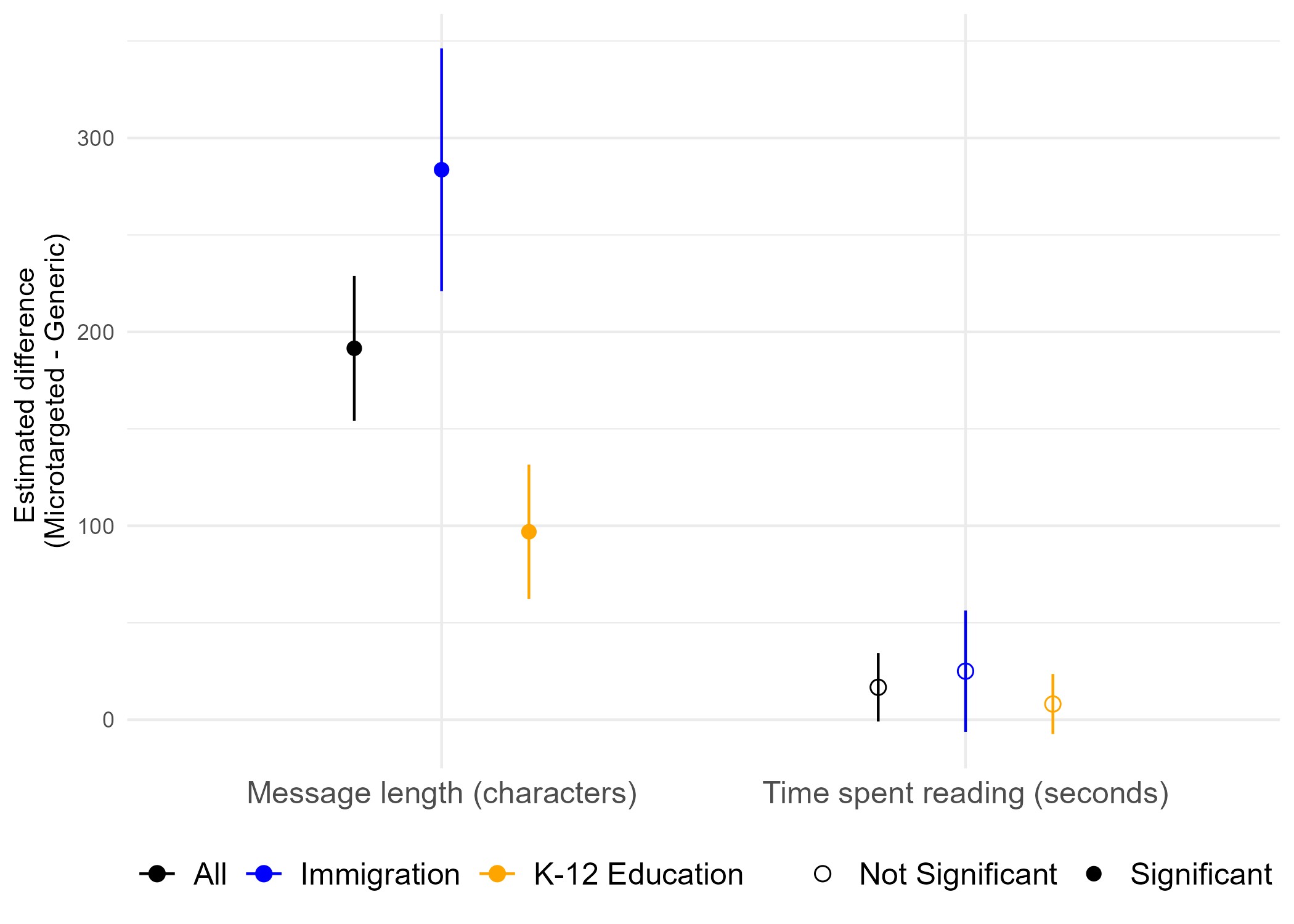
The above graph shows (left) that there were differences in message length - the model generated longer messages while microtargeting than while writing generic messages. This is the case for both topics, though the difference in lengths was more pronounced for the immigration topic. This difference was statistically significant.
On the other hand (on the right side of the graph), we see that there was basically no difference in the amount of time people spent reading the microtargeted and non-targeted messages. This is interesting, since there was a difference in message length. Looks like everyone spent the same time on the page, regardless of how much text there was.
We made a ton of these graphs to compare microtargeted and static messages, and I'm not going to go over all of them here, especially because so many of them show null results. (You can see them in the full paper if you want.) Here are a couple of the highlights:
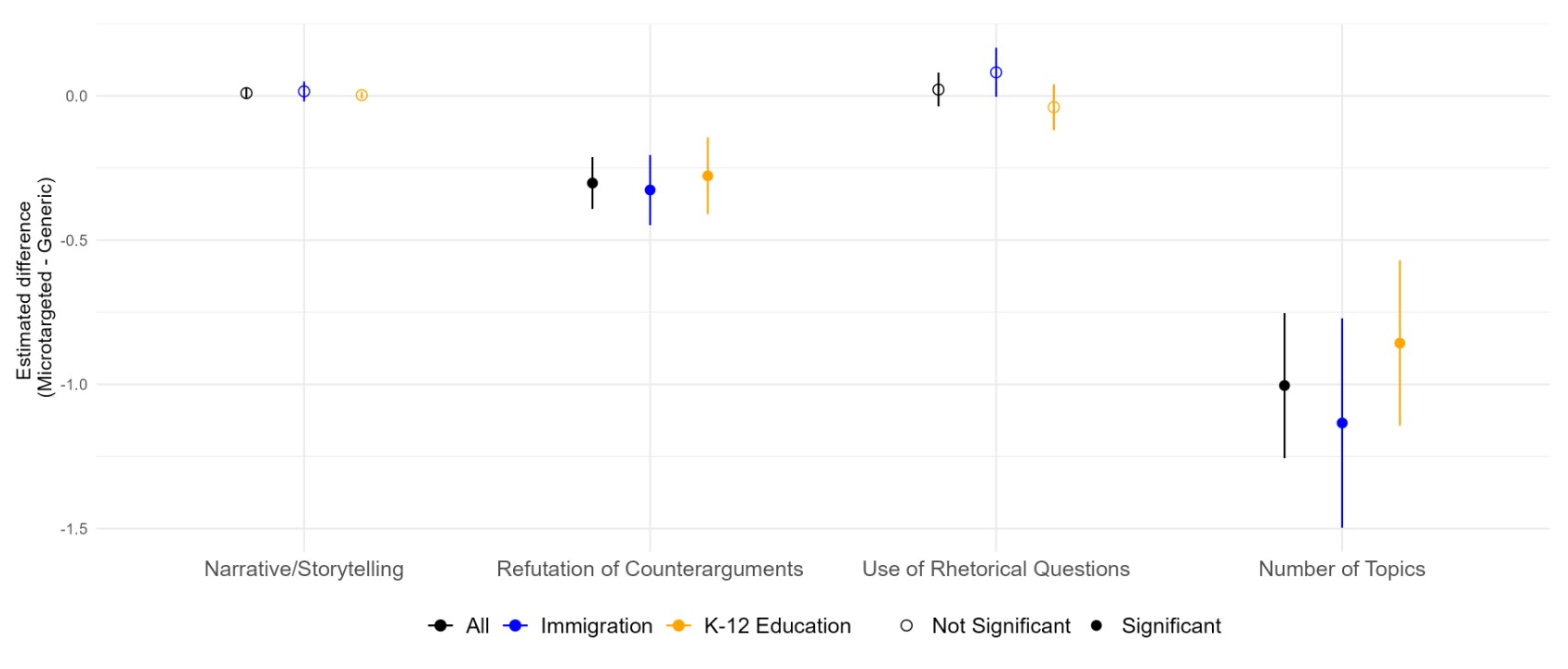
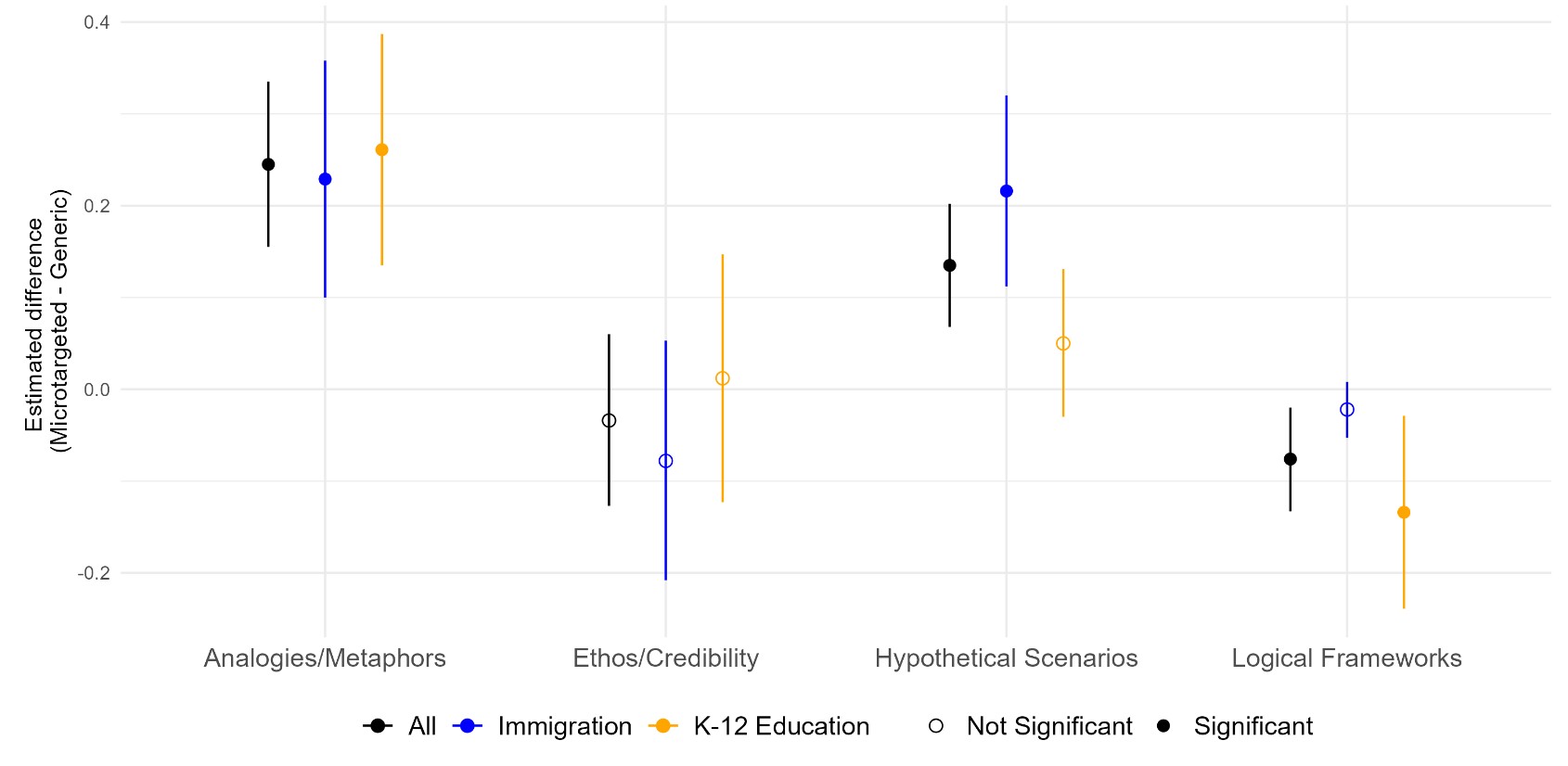
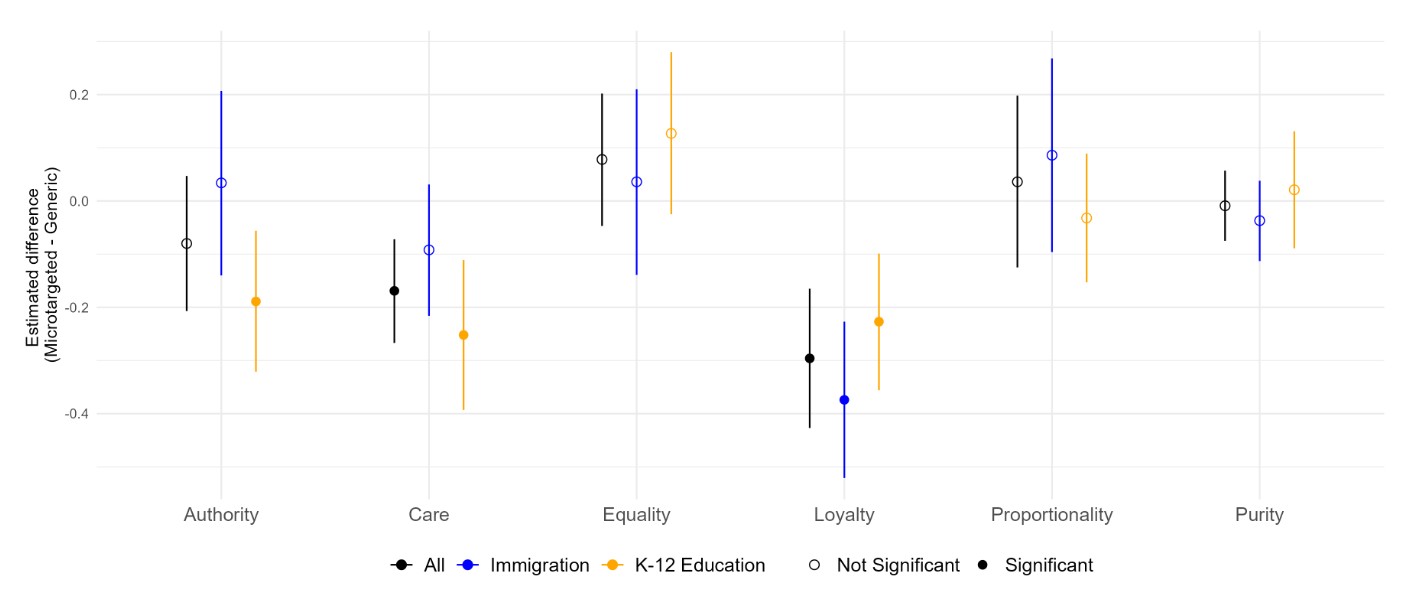
One thing to note here is that the model does use different moral foundations when it talks to liberals and conservatives in a meaningful way. However, this doesn't really differ between static and microtargeted messages.
It turns out microtargeting also has no bearing on whether people were persuaded, or how persuasive they found the messages.
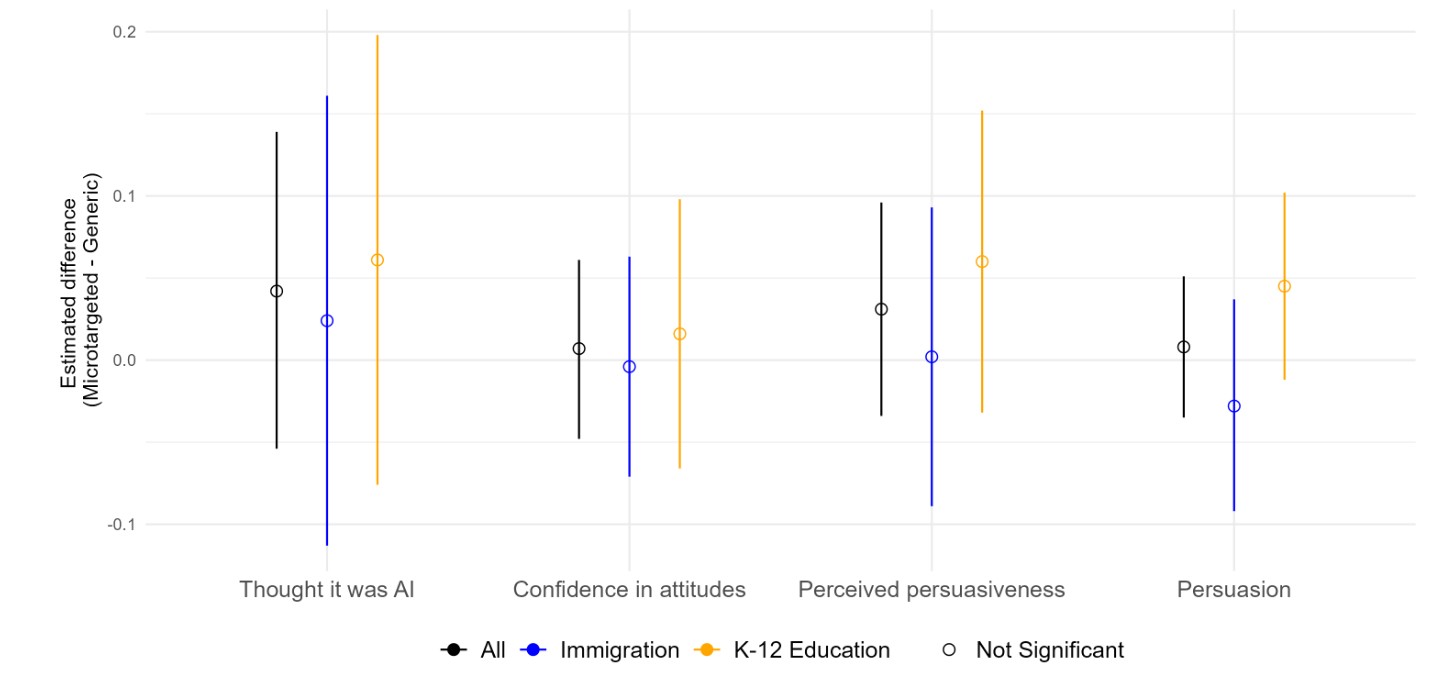
Does the Model Target Systematically Based on Demographics?
To answer this question, we look at correlations. As I mentioned above, we evaluated every single message for tons of different persuasive and rhetorical strategies. The question we're asking is -- do these strategies correlate with any of the respondents' demographics. (For example, does the LLM use more analogies when talking to Atheists?) If the LLM varies its strategies systematically, the demographics where it is targeting would be correlated with the persuasive/rhetorical strategies it is using.
The way we can visualize this is with something called a correlation matrix. Each cell represents the correlation between the variable in the given row and the given column. Here's a correlation matrix: (You may need to zoom in on it.)
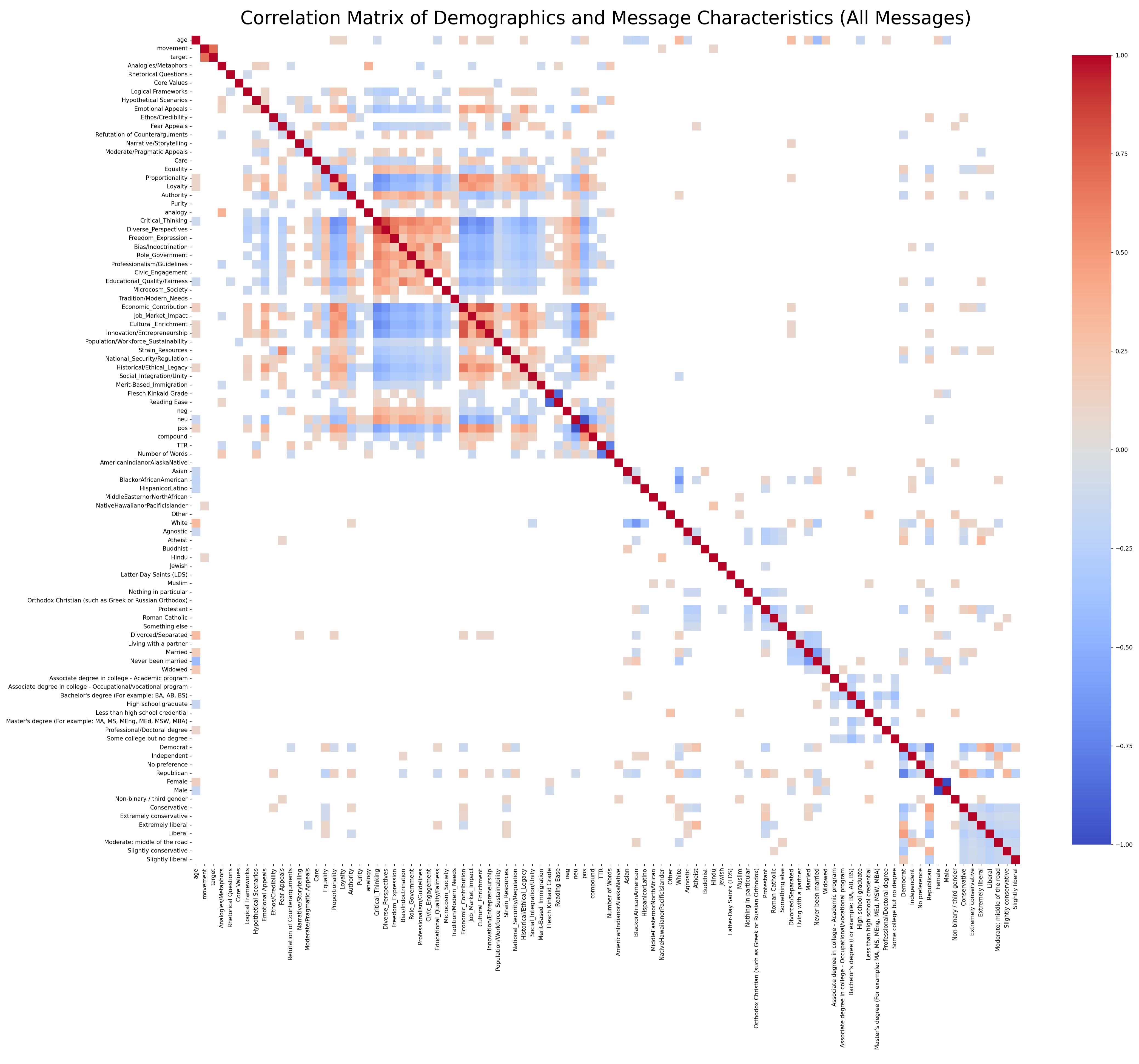
In this graph each cell represents the correlation between two variables. Red means higher positive correlation between the two variables. Blue means greater negative correlation between the two variables. As an example - if you look at where the Flesch Kinkaid Grade, and the Reading Ease, there is a strong negative correlation. That's to be expected. If a text is hard the grade level is high and the reading ease is low.
Most of the correlations we see are like that - If the respondent was never married, that has a low correlation with 'widowed'. But correlations between demographics and demographics aren't that interesting. We're more interested in seeing if demographics correlate with the persuasive strategies the LLM employs. That's (maybe) evidence of microtargeting.
These can be interesting. For example, we see that if the respondent was a Democrat, there's a negative correlation with the model using the Proportionality or Authority moral foundations. (More typical of Conservative morals) Republican party id is positively correlated with those. So from that, we might gather that the LLM is tailoring the moral content of the argument when it knows the person's party identification.
BUT! Social Science is tricky. It's also possible that the model is writing a message in a liberal direction (for example, decrease defense spending). Because of that, the model infers that it is targeting someone who is not already liberal (a conservative). Then, the model might use conservative moral foundations to tailor the argument. Just looking at a correlation matrix doesn't tell us if that is happening or if the model is microtargeting.
What we need to do is see if there is a correlation while the model is microtargeting that is absent when the model is not microtargeting. And the way to do that is pretty easy. We create two of these correlation matrices, one for microtargeted messages, and one for non-microtargeted messages. Then, we subtract the non-microtargeted matrix from the microtargeted one. If there are correlations present in only one condition, they will appear in the difference heatmap. Correlations that appear in both conditions will cancel each other out, and we'll know they aren't attributable to microtargeting.
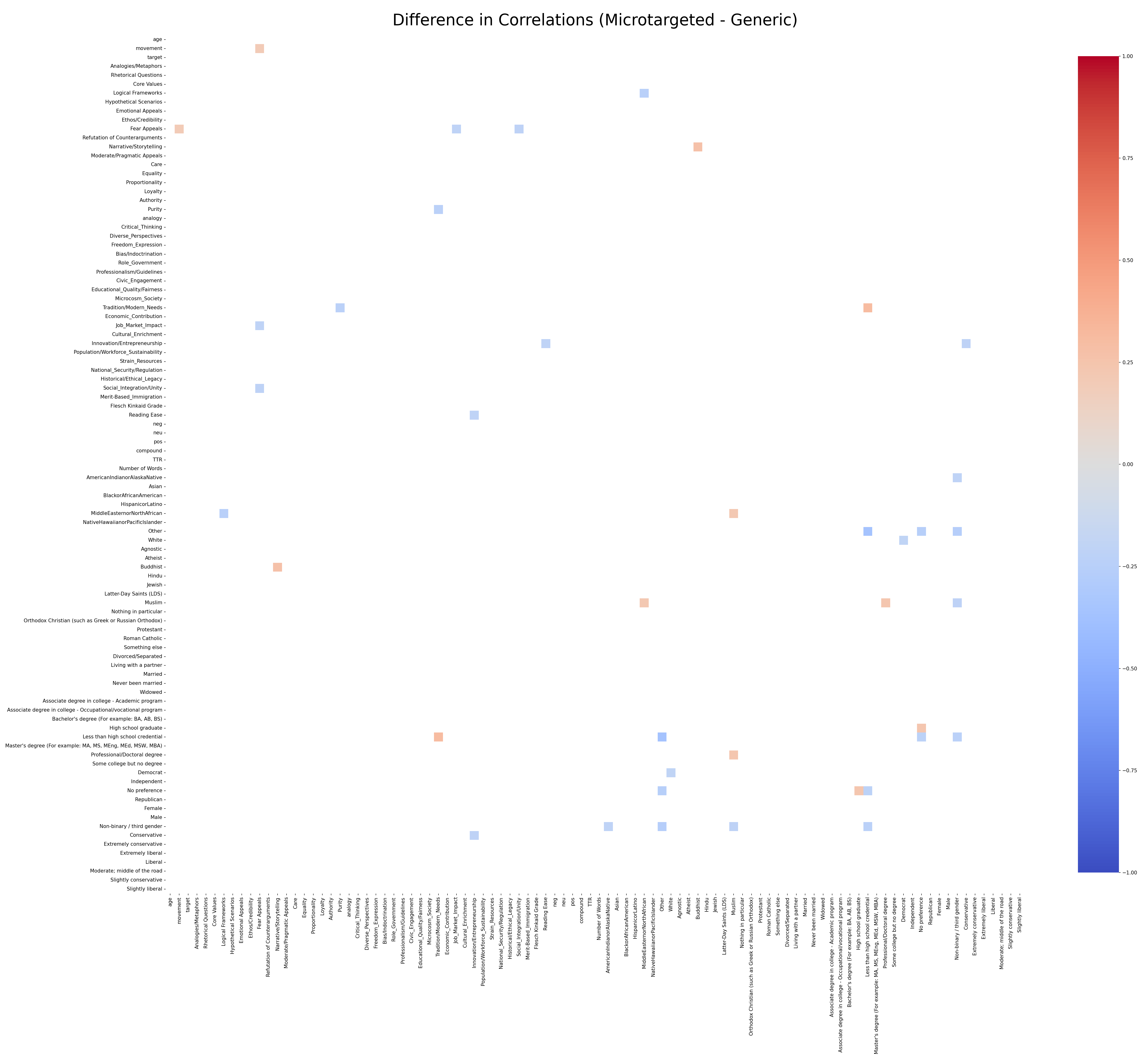
When we take the difference, we just get a few, random cells with values, and they tend to be noise. People who selected 'non-binary/other' as their gender negatively correlate with a few things, but that's just because their sample size is so small (not very many non-binary people in our survey). Overall, this looks like noise, and suggests that the model is not doing any systematic targeting based on the users' demographics. If our model were doing systematic microtargeting, we would see variables about the content of the message correlating with demographic variables only in the microtargeted condition, and there's not evidence of that.
At this point, you might be saying to yourself, "Wait - The first part of the paper showed that the model was microtargeting and that microtargeted messages were different from static ones. Now you're telling me there's no systematic microtargeting? How can those both be true?"
Great question! A lack of systematic microtargeting just means that the microtargeted messages don't correlate differently with the respondents' demographics. However, that doesn't mean that microtarget messages don't differ from regular messages, just that the way they differ doesn't correlate with the demographic information we gave the model in our experiments.
Can a Model Guess Demographics from Messages?
If microtargeting is happening, and correlates with demographics, one might assume that a different version of the model that had never seen the person's demographics could infer them based on the microtargeted message. You could think of it as reverse-engineering the person from the microtargeting. We tried this, and the model generally couldn't guess things about the respondents better with microtargeted messages. There's a teeny bit of ability to guess political ideology, but that's about all.
Study 2
Once we got to this point, we were a little bit worried that the paper would be a 'capabilities paper', where we are essentially just saying, "GPT-4 (the model we used in the study) doesn't microtarget specifically on demographics, but it does write different messages while targeing." That's maybe a little bit useful, but GPT-4 is out of date. To solve this, we give the exact same prompts from the original study to generate messages with 3 other state-of-the-art LLMs. We chose both open- and closed-weight models from three different companies:
- GPT-5 (OpenAI)
- Qwen3 Next 80B (Alibaba)
- Gemma3 27B (Google)
As a note, it is generally a bad idea to reuse prompts from one LLM on another LLM, especially one from a different family. Differences in training data and methodology make models behave differently. However, we decided to reuse the same prompts from the original study because microtargeting is very tricky to define, and we wanted to ensure a consistent task definition. Because the prompt was created and optimized for GPT-4, we would expect GPT-4 to do the best with the prompt.
To visualize what was going on, we started out by embedding all of the messages from all 4 models.
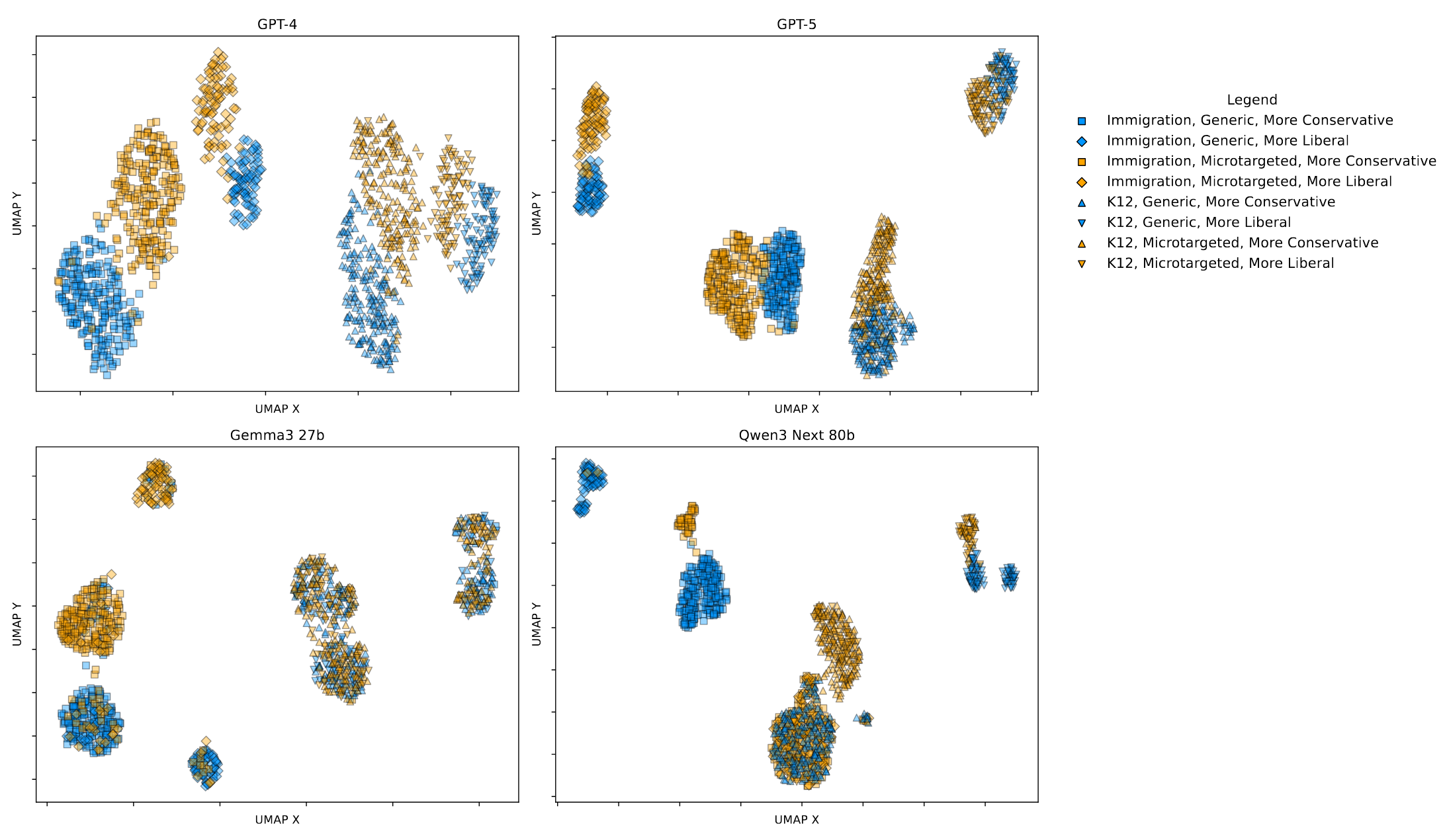
We can see that the models do not all appear to perform the task the same way. GPT-5 seems to do basically the same thing as GPT-4 (but with tighter clusters, indicating greater similarity between messages within conditions). Gemma3 separates pretty cleanly in the Immigration condition, but it looks like there's lots of overlap in the K12 condition. Qwen3 shows separation based on topic and direction, but also has one gigantic lump of leftovers taken from all the topics/conditions.
It seems like the GPT models are better at microtargeting than the other models we tested. It clearly writes different messages based on argument and targeting in a better way than Gemma and Qwen.
The Appendix
We got the whole paper written, and then I somehow got roped into creating and formatting the appendix. It was a bear of a job, and more than half of it was charts and prompts I had created. Unless you're really interested in particulars, I can't imagine why you'd want to read the appendix, but since I put so much work into it I figured I'd make it available here.
Conclusion
As with all of my papers, you can read it if you want. The paper is way longer than this blog post (over 30 pages), and much more technical. I host an unofficial copy here, and you can check out the official version here (if you have institutional access to Chinese Political Science Review). I want to close this post with a special thanks to my co-author and friend, Ethan Busby. This paper wouldn't have happened without all his work.