ADoBo at IberLEF 2025
As I have for the last few summers, I entered another academic competition.
Shared Tasks at Academic Conferences
In the CS world, academic conferences often include Shared Tasks, which are a sort of challenge. The task organizers want to encourage research in a specific area, so they formalize a task and challenge researchers to come up with good solutions. Participants in the challenge submit solutions, as well as technical reports detailing their methods. This increases the number of people working on that task.
Two years ago, I got third place in a computer vision shared task at CVPR. Last year, my BabyLM challenge entry took me to Miami for EMNLP. This year, I prepared an entry for the ADoBo challenge at IberLEF 2025.
ADoBo
This year's challenge is a very linguistics-oriented task. I like to do at least one linguistics thing each year to keep my skills sharp. This years task is at IberLEF, the Iberian Language Evaluation Forum in Zaragoza, Spain.
ADoBo stands for Automatic Detection of Borrowings. From the description on the shared task website,
"[W]e propose a shared task on retrieving anglicisms from Spanish text, i.e. words borrowed especifically from English that have recently been imported into the Spanish language (words like running, smartwatch, influencer or youtuber).
The test set will consist of a collection of sentences written in European Spanish from the journalistic domain. Participants will be required to run their systems on the given sentences and return the anglicism spans in the sentence. For example, given the sentence:
"Al no tener equipo de ventas, ni 'country managers' ni hacer mucho marketing, no tenemos grandes costes."
The correct output should be:
country managers; marketing"
So that's the idea. The challenge is to create a system that can detect the English borrowings in a sentence. Seems pretty straightforward.
Challenges
It turns out this isn't as especifically as one might hope.
If you imagine the simplest solution, you might grab a Spanish dictionary. For each word in the sentence, you look up the word in the dictionary. If it's not in the Spanish dictionary, you consider it an Anglicism.
But this probably wouldn't work super well. What happens when you run into a word like normal? This word is the same in Spanish and English. The dictionary approach also can't consider multi-word phrases. So in the example above, it would consider country and managers separately instead of as one entity, which is wrong. This approach would also suffer when you run into Spanish words that aren't in your dictionary. Things like names, slang, and misspellings would all be incorrectly identified as Anglicisms. Non-Spanish, Non-English words would also be identified as Anglicisms.
On top of all this, it turns out the definition of Anglicism is WAY more complex than the example above. Here's a flowchart designed to help people determine whether or not to annotate a word as an Anglicism.
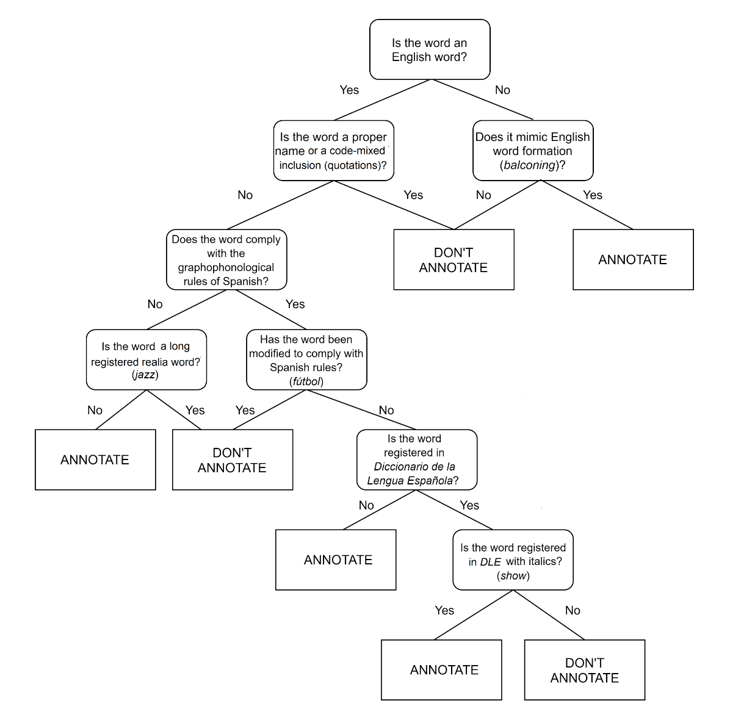
So how did I decide to tackle the problem?
The solution seemed obvious to me: use a Large Language Model to annotate the sentences.
This approach has several advantages:
- Knowledge: LLMs have explicit and implicit knowledge of both English and Spanish.
- Development time: You don't need to train a new model, you can just prompt an LLM to complete the task.
- Low cost: LLM usage through an API is relatively inexpensive.
The task organizers provided a development set, which was about 1900 sentences with the Anglicisms already identified. I could use this to train my model. Once the models were trained, they also provided a test set of sentences without the Anglicisms identified. After developing a system, I could run the test set through it as a final test. My job was to run it through my system and turn it in for scoring.
Finding the Right Prompt
The first thing I did with my data was split it up into train, test, and validation sets. This let me use the train and test sets to refine my approach before finalizing it on a validation set of sentences the model hadn't seen. This would give me a good idea of how well the approach would generalize to the unseen data for the final scoring.
I knew that I wanted to use a commercial LLM for the task, but I still had to figure out a lot of things:
- What prompting techniques would be most effective?
- How many instructions would the model need to carry out the task?
- Which model should I use?
I knew that larger models tend to be more capable but also more expensive. The the other questions needed to be answered through careful experimentation.
Variable 1: Tell vs Show
What is the best way to specify to a language model exactly what you want it to do? There are two main approaches: telling and showing.
LLMs are capable of something called in-context learning (ICL). This means that if you show a language model a few examples of how it should complete a task, it can pick up on the task. This tactic, called few-shot prompting, is both effective and widely used.
On the other hand, modern LLMs are explicitly trained on thousands of examples of how to follow instructions. This means that telling is sometimes more effective than showing.
In order to tease this apart, we tried a few prompt variations. We started with a basic baseline prompt:
Given the following Spanish sentence, identify all anglicisms.
An anglicism is a word or multi-word expression borrowed specifically from English that has recently been imported into the Spanish language and is used without orthographic adaptation.
Examples of anglicisms include 'running', 'smartwatch', 'influencer', 'country managers', 'marketing'.
This is the sentence to evaluate:
{sentence}
Output only the identified anglicisms, separated by semicolons. If no anglicisms are found, output 'None'.
To create the 'show' (few-shot) prompt, I inserted some examples of Anglicism detection from my smaller training set. I also wanted to see how many examples would be useful, so I had a reasoning LLM read through the training set and choose sets of five, ten, and twenty-five representative sentences to use.
To create the 'tell' prompt, I found a guide online that was used by humans to identify Anglicisms and create the ground-truth data for the task. It was a 20 page pdf, so I fed the pdf to the same reasoning LLM and had it boil the document down into a short set of guidelines detailing how to do the task, including edge cases. Feel free to skip these, or read them if you want.
The following rules provide a robust, step-by-step protocol for identifying emergent, unassimilated English lexical borrowings (anglicisms) in Spanish text.
1. Initial Identification
- Determine if the word or multiword expression is of English origin or mimics English word formation.
- If the word is not of English origin, do not consider it an anglicism.
- If it mimics English formation but does not exist in English (pseudoanglicism, e.g., balconing), consider it an anglicism.
2. Exclusion of Proper Names and Code-Mixed Inclusions
- If the word is a proper noun (person, organization, product, location, event, etc.) or a direct code-mixed quotation, do not consider it an anglicism.
- Borrowings embedded within proper nouns or named entities do not count, unless the proper noun is part of a multiword borrowing used grammatically as in English (e.g., Google cooking is annotated).
3. Graphophonological Compliance
- If the word's spelling and pronunciation conform to Spanish graphophonological rules (e.g., bar, club), proceed to dictionary checks.
- If not (e.g., show, look), generally consider it an anglicism unless it is a long-registered realia word (see Rule 5).
4. Adaptation and Assimilation Status
- If the word has been morphologically or orthographically adapted to Spanish (e.g., fútbol, tuit, líder), do not consider it an anglicism.
- If the word remains unadapted, continue to dictionary checks.
5. Dictionary Verification
- If the unadapted word is registered in the Diccionario de la Lengua Española (DLE):
- If it appears in italics, consider it an anglicism.
- If it appears without italics and with the relevant meaning, do not consider it an anglicism (it is considered assimilated).
- If it is not registered or not with the relevant meaning, consider it an anglicism.
- For multi-sense words (e.g., top), only consider them an anglicism when used with unregistered meanings.
6. Realia and Long-Registered Borrowings
- If the word is a long-registered realia borrowing (cultural terms like jazz, pizza, whisky, club), do not consider it an anglicism, even if unadapted.
- If the word is a recent or emergent realia borrowing not yet registered, consider it an anglicism.
7. Multiword Borrowings
- Do consider multiword expressions borrowed as a unit from English (e.g., reality show, best seller).
- For adjacent borrowings not forming a fixed English phrase (e.g., look sporty), select each word separately.
8. Exclusions and Special Cases
- Do not consider an anglicism:
- Latinisms, scientific units, species names, acronyms (unless part of a multiword borrowing), or digits in isolation.
- Metalinguistic usages, literal quotations, or code-switched expressions not integrated into the sentence.
- Names of peoples or languages, and words derived transparently from proper nouns (e.g., un iPhone, un whatsapp).
- Do consider an anglicism:
- Pseudoanglicisms (Spanish-coined words mimicking English, e.g., footing, balconing).
- Unadapted names of fictitious creatures (e.g., hobbit, troll).
- Borrowings embedded in compounds or prefixed forms, if the borrowed element retains independence (e.g., ex influencer, nano influencers).
Tell vs Show isn't a binary. You can give both instructions and examples, so we tried this too.
Variable 2: Chain-of-Thought Prompting
Chain-of-Thought prompting is a technique where you encourage the language model to think step-by-step before outputting the final answer. This tends to improve model performance, and can be very effective. To do this, I appended this to the prompts:
First, think step-by-step about which words/phrases might be anglicisms and why.
After thinking things through, on a new line, output only the identified anglicisms, separated by semicolons. If no anglicisms are found, output 'None'.
Variable 3: Model Selection
How do you know which model to use? There's a tradeoff between model size (bigger is usually better) and cost (bigger is usually more expensive). To test this, I ran my experiments with many of OpenAI's GPT-4.1 series, all of which are in the latest generation of LLMs at the time of experimentation.
- GPT-4.1 nano
- GPT-4.1 mini
- GPT-4.1
I also tried two of OpenAI's reasoning models.
- o4 mini
- o3
Reasoning models are essentially models that have been trained explicitly to reason through a chain-of-thought reasoning process without needing to be prompted to do so.
The model pricing varies wildly with o3 costing 100 times what 4.1 nano costs. ($10 per million tokens instead of 10 cents per million tokens.) None of those are too expensive, actually. Running GPT-4.1 with chain-of-thought on one sentence costs about half a cent. Running GPT-4.1 nano without chain-of-thought for one sentence costs about 0.01 cents. Interestingly, running a model that's 100 times more expensive doesn't get you a 100x increase in performance.
Variable 4: Self Refinement
Language models are able to refine their own prompts and outputs. After testing our models on our test set, we take the results and have a different reasoning model (R1 1776) evaluate all of the results. The model then boiled down the list of successes and failures into a set of additional guidelines.
So how did performance vary across models and prompts?
Results
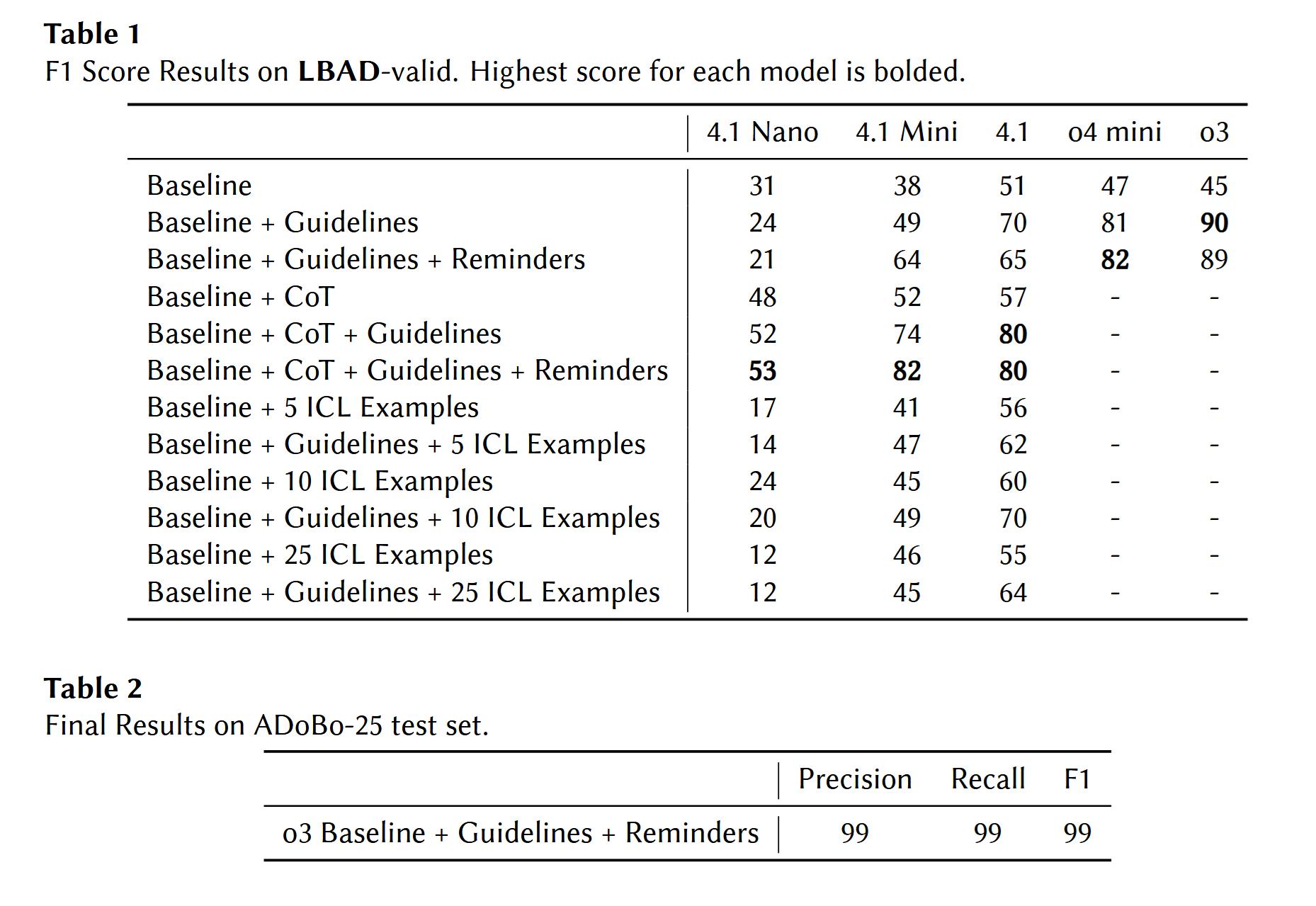
We see that adding detailed instructions was very important. The basic prompt underspecified the complexities of the task, and the LLM had to infer what exactly constitutes an Anglicism.
On top of this, we tested both ICL and CoT prompting with and without the detailed instructions. As you can see from the chart, ICL examples were not more effective than instructions. (Telling worked better than showing.)
Chain-of-Thought reasoning was super effective. While detailed instructions were vital to the models' understanding of the task, CoT allowed the models to reason through the complex detection process. Self-refinement provided mild benefits, but nothing huge.
Conclusion
I won the competition! The competition was scored using the F1 score, which is a measure that captures both recall (correctly identifying Anglicisms) and precision (not identifying non-Anglicisms as Anglicisms). The o3 reasoning model with detailed instructions and reminders achieved 99% accuracy on the final leaderboard.
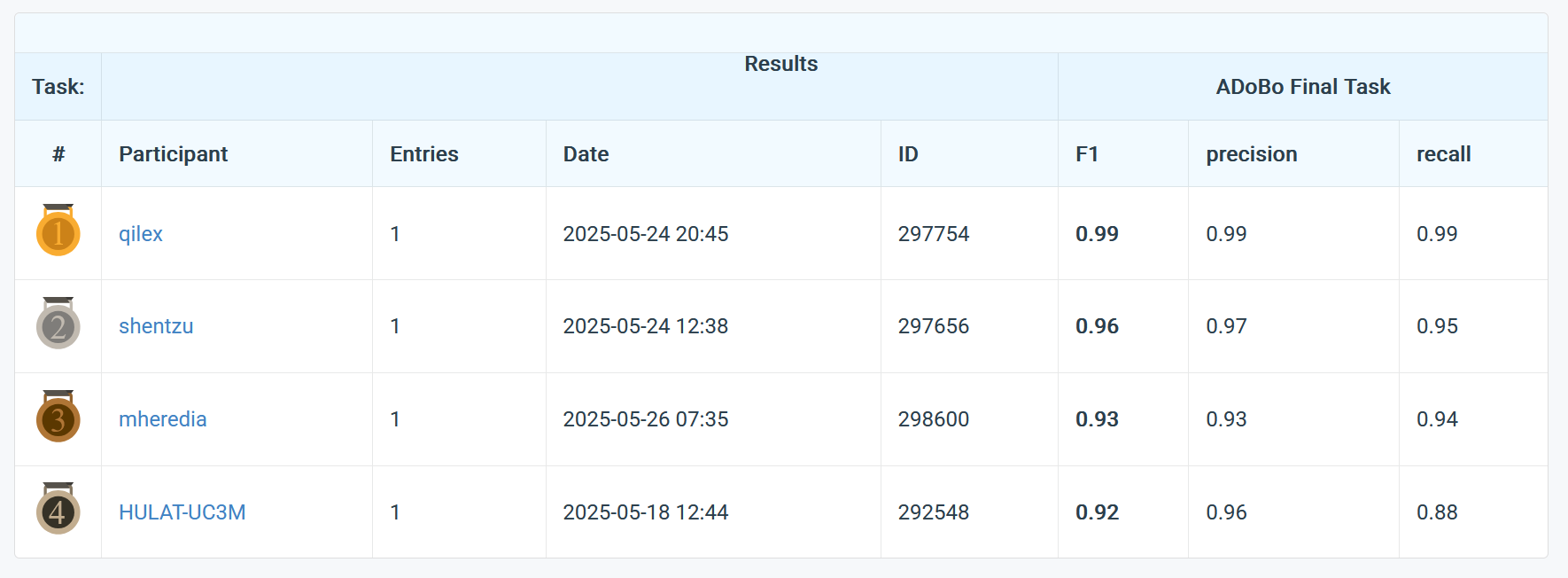
Our best model got 99% accuracy on the final task, which was great. Looking at that last 1% is very informative, since it tells us how the model fails. Almost all of the failures fall into two categories: multi-word issues and orthographic challenges. About 1/3 of the mistakes happen when the model will identify an Anglicism like "Casual Looks" as two separate Anglicisms, "Casual" and "Looks". The other 2/3 happen with words like normal, total, and error. These words are spelled the same in both English and Spanish and have similar meanings in both languages. This is a very tricky edge case, so it's not the end of the world that the model got it wrong sometimes.
In conjunction with this competition, I prepared a technical report and submitted the manuscript to the conference (it has been accepted) that talks about all of this in detail. You can read it here.