Color pAI: Categorizing Magic Cards Based on Text
I train a model to predict a Magic card's color based only on its rules text.
Introduction
In order to understand this post, you're going to need to know a little bit about Magic: the Gathering. We've covered some of this in other posts, but we're going to do a little bit of a deep dive here.
The Color Pie
In Magic, there are 5 colors: White, Blue, Black, Red, and Green.
Each color represents a different type of magic, and has its own gameplay strengths and weaknesses.
The game's design team sticks to something called the 'Color Pie', which assigns different gameplay mechanics to each color.
If each color is qualitatively different from the others, we should be able to teach a model how to identify a card's color from its rules text.
Here's a quick overview of the design philosophy of the 5 Magic: the Gathering colors.
White




White is the color of justice and valor. As far as gameplay goes, white is the color of gaining life, of granting bonuses to all of your small creatures, and of exiling opposing creatures.
Blue




Blue is the color of cunning and intelligence. In gameplay terms, blue cards counter opposing spells, draw you more cards, and mill your opponents (put cards directly from their deck into their graveyard).
Black




Black is the color of death and decay. In the game, black cards destroy opposing creatures, return your creatures from the graveyard, and allow you to pay your own life for added benefits.
Red




Red is the color of rage and speed. In gameplay, red cards deal direct damage to opposing creatures and players, many red creatures can attack the turn they come into play, and red cards can destroy opposing artifacts.
Green




Green is the color of savagery and strength. Green creatures are the biggest and strongest of any color and green spells can put lands directly into play or give massive bonuses to your creatures' stats.
What are we trying to do?
Since each card's colors should be represented by its gameplay rules text, it would follow that a strong model should be pretty accurate at predicting a card's color based soley on its text. We want to create that sufficiently strong model. We are simplifying this task. While Magic has 5 colors, there are also colorless and multicolored cards. For this example, we only consider monocolored and colorless cards.
Problems with the task
Predicting a card's color based on its rules text is not possible 100% of the time. Consider the following example:




These cards are all different colors and all have the same rules text, nothing! (We're not using the italicized flavor text.)
We can't expect even the smartest model to correctly classify them based only on the fact they have no rules text.
Additionally, the Color Pie as it now exists hasn't always been around in its current form.
Some cards (particularly old ones) are considered color pie breaks, where they have abilities they shouldn't based on their colors.
In spite of these difficulties, we're still going to and build the model and see how it performs.
Since there are 6 possible categories, a model randomly selecting one of the categories would be right 1/6 of the time.
That's an accuracy of about 17%, so we'll hope to beat that.
BERT
In 2019, the NLP (Natural Language Processing) world was revolutionized when Google released BERT, a transformer-based language model.
If you've been reading this blog for a while, you've heard all about language models by now.
If not, a language model is an advanced machine learning model that tries to capture the underlying probabity distribution of language.
BERT was trained on all of English Wikipedia and a substantive portion of the Google Books corpus, and it essentially 'knows' how English works.
I've never actually used vanilla BERT-base for a task before, so I wanted a chance to try it out, even though better language models have been published in the years since BERT's release.
Data
We train our model on the rules text from roughly 15,000 magic cards.
This card text is available as a bulk download in JSON format from Scyfall, which makes collecting our data a breeze.
Once our data is collected, we need to do a couple of data preprocessing steps. Many Magic cards have activated abilities that include mana symbols, which are color indicators.
If we feed those into our model, it can 'cheat' and rely on these mana symbols for its predictions.
We replace all colored mana symbols with the token {U} to prevent this 'cheating' and force our model to make predictions based only on the card's text.
Since we want this model only to consider the gameplay mechanics and not Magic lore, we don't use the italicized flavor text.
However, cards' names often contain lore words, so any time a card's name appears in its rules text we replace it with the special token CARDNAME.
Training the Model
Training the model is straightforward. We download the model from Huggingface and we can fine-tune it in less than 15 minutes (on my 8GB GPU). Here's a great tutorial on how to do something similar.
Testing the Model
Once our model is trained, we test it on a bunch of cards it's never seen before to get its accuracy.
If you remeber, random chance is 17%, which is what we're trying to beat.
Our model gets a whopping 70.3% accuracy on a validation set of cards it's never seen before.
We can test out the model at the interactive demo on a new card that's come out since the model was trained.
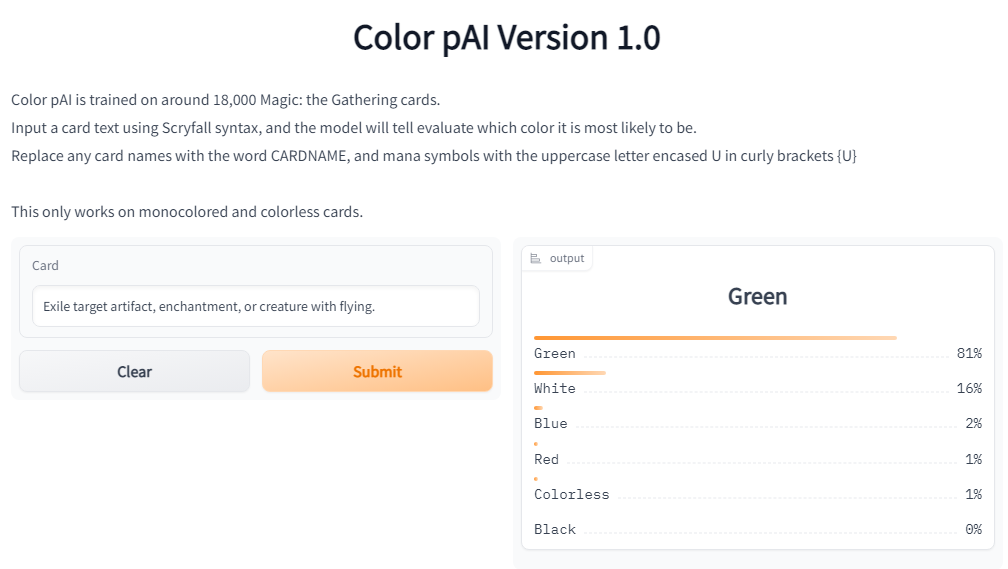
Try it out!
You don't have to take my word for it, you can try the interactive demo here. Since new Magic cards are released every couple of months, you can try it on new cards that have come out since I trained this model in August 2022. Give it a whirl!
Acknowledgements
- Data for this project, including the images on this post, was provided by Scyfall and used in accordance with the Wizards of the Coast fan content policy.